Wer heute einen produktionsreifen Sprachagenten bauen will, kämpft selten mit der KI-Intelligenz – sondern mit der Infrastruktur darunter. Latenz, Unterbrechungsbehandlung, skalierbare Deployments: Das sind die Probleme, die zwischen einem funktionierenden Demo und einem echten Produkt stehen. Pipecat, das Open-Source-Python-Framework von Daily.co, adressiert genau diese Lücke. Seit seinem GitHub-Launch 2024 haben über 1.000 Teams das Framework in der Beta-Phase erprobt, und seit Januar 2026 ist die zugehörige Cloud-Lösung allgemein verfügbar.
Dieser Guide richtet sich an Python-Entwickler und KI-Ingenieure mit Grundkenntnissen in asynchroner Programmierung. Er führt von der Architektur über Web- und Hardware-Integrationen bis hin zum produktionsreifen Deployment – inklusive direktem Vergleich mit LiveKit.
Key Takeaways
Pipecat ist ein quelloffenes Python-Framework für Echtzeit-Sprach-KI-Pipelines mit 500–800 ms End-to-End-Latenz und über 100 integrierten KI-Diensten.
- Modulare Pipeline: Jeder Schritt – STT, LLM, TTS – ist ein austauschbarer Frame-Prozessor; keine Vendor-Bindung.
- Der Pipeline-Produktions-Gap: Die Lücke zwischen Quickstart-Prototyp und produktionsreifem Agenten schließt die Architektur durch eingebautes Interruption Handling und Transport-Abstraktion.
- Deployment-Optionen: Self-Hosting via Docker oder verwaltetes Hosting – derselbe Code, unterschiedliche Skalierungsphilosophie.
- Stärken vs. LiveKit: Die Lösung gewinnt bei Flexibilität und Provider-Austauschbarkeit; LiveKit punktet bei nativer WebRTC-Infrastruktur und etwas niedrigerer Baseline-Latenz.
Was ist Pipecat?
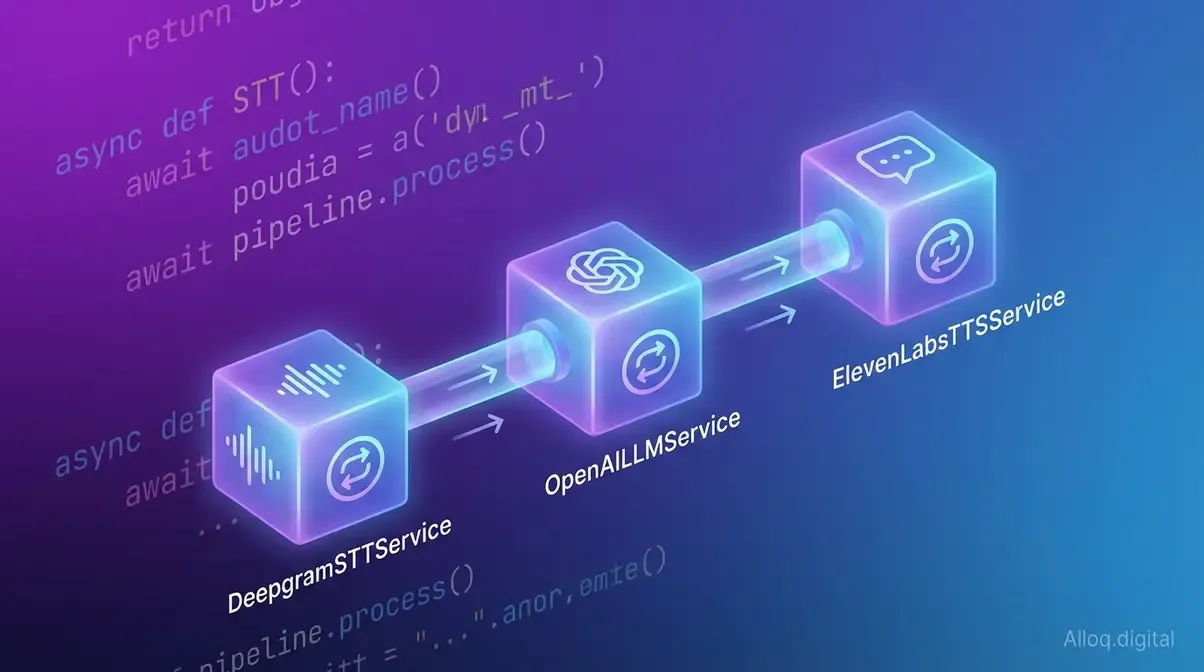
 Pipecat verbindet über 100 KI-Dienste in einer einzigen asynchronen Pipeline - von Deepgram STT über OpenAI LLM bis ElevenLabs TTS.
Pipecat verbindet über 100 KI-Dienste in einer einzigen asynchronen Pipeline - von Deepgram STT über OpenAI LLM bis ElevenLabs TTS.
Pipecat ist ein quelloffenes Python-Framework für die Entwicklung von Echtzeit-Sprach-KI-Agenten und multimodalen Konversationsagenten. Es orchestriert über 100 KI-Dienste – von Spracherkennungs-APIs über Large Language Models bis zu Text-to-Speech-Systemen – innerhalb einer einzigen asynchronen Pipeline mit 500–800 ms End-to-End-Latenz (Pipecat Docs, 2026). Damit ist die Bibliothek im offiziellen Python Package Index verfügbar und unter der BSD-3-Clause-Lizenz veröffentlicht.
Von der Idee zum Open-Source-Standard
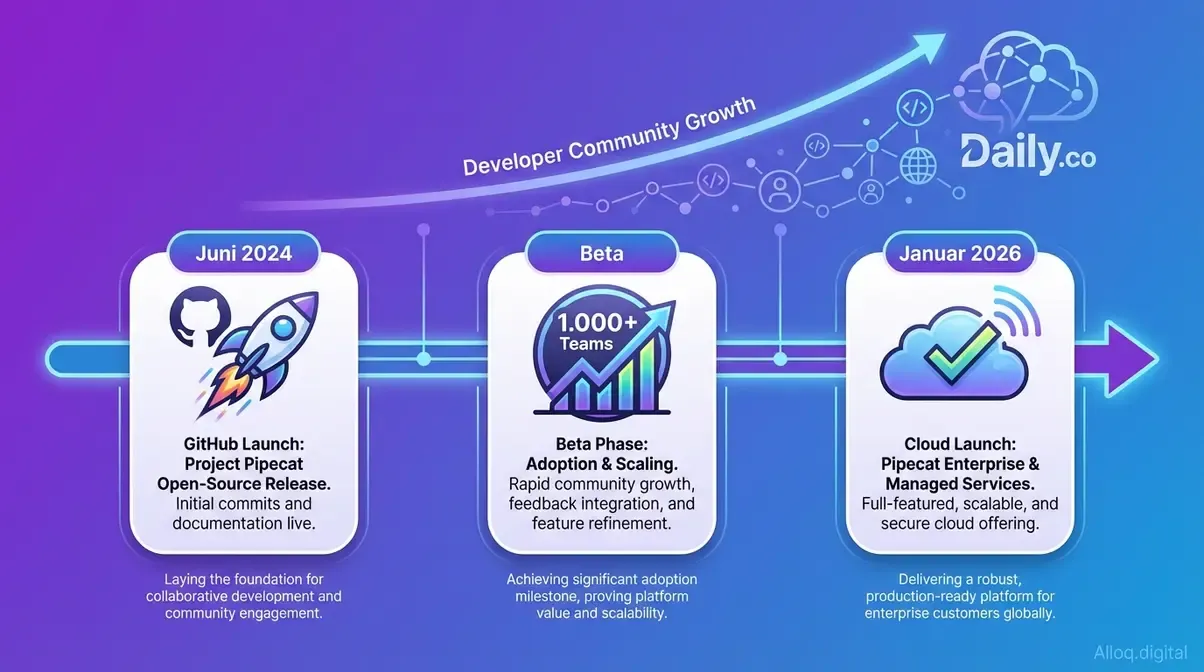 Von Daily.co intern entwickelt zum Open-Source-Standard: Pipecat zählt seit dem GitHub-Launch 2024 über 1.000 aktive Teams - Cloud-GA seit Januar 2026.
Von Daily.co intern entwickelt zum Open-Source-Standard: Pipecat zählt seit dem GitHub-Launch 2024 über 1.000 aktive Teams - Cloud-GA seit Januar 2026.
Daily.co, das Unternehmen hinter der Entwicklung, veröffentlichte das Tool im Juni 2024 auf GitHub. Die Entstehungsgeschichte folgt einer Logik, die viele Entwickler kennen: Das interne Team hatte das Grundgerüst bereits für eigene Sprachagenten gebaut, bevor die Entscheidung fiel, es als Open-Source-Projekt zu öffnen. Seit dem Launch zählt das Repository über 1.000 aktive Teams in der Beta-Phase – Tendenz steigend, was sich auch im stark wachsenden Suchvolumen widerspiegelt.
Das System positioniert sich explizit als Gegenentwurf zu vollständig verwalteten Plattformen wie VAPI oder Retell AI. Die Philosophie: Entwickler sollen volle Kontrolle über ihre Datenströme behalten, dabei aber nicht jede Komponente von Grund auf neu schreiben müssen. Das Basis-Framework liefert die Infrastruktur – Routing, Queuing, Lifecycle-Management –, während Modelle und Dienste frei wählbar bleiben.
Für Entwickler, die bereits mit OpenClaw und KI-Agenten-Architekturen gearbeitet haben, ist das Paradigma vertraut: Agenten sind modulare, erweiterbare Einheiten – kein Monolith.
Kernfunktionen im Überblick
Die Engine baut auf drei Kernprinzipien auf, die es von alternativen Ansätzen unterscheiden:
Frame-basierte Verarbeitung: Alle Daten im System – Audiofragmente, Transkriptionen, LLM-Ausgaben – werden als typisierte Frames durch die Applikation geleitet. InputAudioRawFrame, TranscriptionFrame, LLMTextFrame und OutputAudioRawFrame sind keine abstrakten Konzepte, sondern konkrete Klassen, die sich direkt in Python handhaben lassen.
Transport-Abstraktion: Die Architektur trennt strikt zwischen dem KI-Logik-Layer und dem Transport-Layer. WebRTC, WebSockets, lokale Audio-Streams – all das wird hinter einer einheitlichen Transport-Klasse abstrahiert. Welche Übertragungstechnologie genutzt wird, ist intern irrelevant.
Async-native Struktur: Der Kern ist von Grund auf für Python-Asyncio entwickelt. Frames werden nicht blockierend verarbeitet, Queues sind eingebaut. Das erlaubt es, Echtzeitanforderungen zu erfüllen, ohne manuelle Thread-Verwaltung betreiben zu müssen.
Unterstützte Integrations-Kategorien umfassen: STT (Deepgram, AssemblyAI, Whisper), LLM (OpenAI, Anthropic, Google Gemini, Amazon Bedrock/Nova), TTS (ElevenLabs, Cartesia, Azure), sowie Transport-Backends (Daily WebRTC, WebSocket, Local).
Kosten und Open-Source-Lizenz
Das Framework selbst ist vollständig kostenlos und quelloffen (BSD-3-Clause-Lizenz). Die Kosten entstehen durch die genutzten Drittanbieter-APIs: Deepgram berechnet nach Transkriptionsminuten, ElevenLabs nach generierten Zeichen, OpenAI nach Tokens. Eine Kostenanalyse von Neuphonic zeigt, dass die effektiven Gesamtkosten stark vom gewählten Provider-Stack abhängen – und durch den Austausch einzelner Komponenten erheblich optimiert werden können.
Die Cloud-Version, die verwaltete Hosting-Plattform, wird separat abgerechnet: aktive Agenten-Instanzen kosten deutlich mehr als reservierte (Stand-by-)Instanzen, die lediglich 1/20 des Preises aktiver Instanzen ausmachen (Daily.co, 2026).
Die modulare Pipeline-Architektur
 Die modulare Pipeline erlaubt den unabhängigen Austausch jedes Prozessors - STT, LLM oder TTS - ohne Einfluss auf die übrigen Komponenten.
Die modulare Pipeline erlaubt den unabhängigen Austausch jedes Prozessors - STT, LLM oder TTS - ohne Einfluss auf die übrigen Komponenten.
Eine typische KI-Pipeline ist kein Flowchart auf Papier – sie ist ein laufendes, asynchrones Datenrohrsystem. Jeder Sprach-Frame durchläuft einen definierten Pfad: von der Audioeingabe über Spracherkennung und Sprachmodell bis zur Sprachausgabe. Das Besondere: Dieser Pfad ist modular konfigurierbar, und genau diese Modularität schließt den Pipeline-Produktions-Gap – die Lücke zwischen einem laufenden Demo und einem echten Produktionssystem.
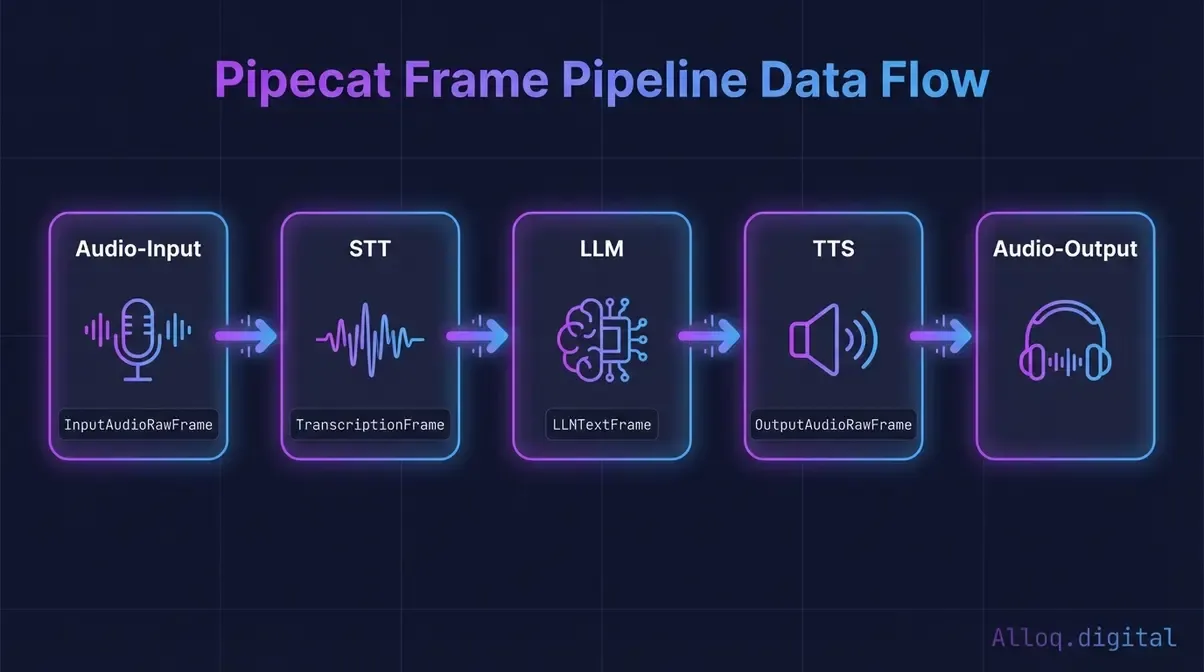 Der Frame-Fluss in einer Standard-Pipecat-Pipeline: Jeder Prozessor transformiert eingehende Frames und gibt typisierte Frames an den nächsten Schritt weiter.
Der Frame-Fluss in einer Standard-Pipecat-Pipeline: Jeder Prozessor transformiert eingehende Frames und gibt typisierte Frames an den nächsten Schritt weiter.
Caption: Der Frame-Fluss in einer Standard-Pipeline: Jeder Prozessor transformiert eingehende Frames und gibt neue Frames weiter.
Der Frame-Fluss: STT zu TTS
Der Datenfluss folgt einem klar definierten Muster. Verstehen Entwickler dieses Muster, können sie jeden Schritt unabhängig austauschen oder erweitern – ohne den Rest des Systems zu berühren.
Ein minimales Setup in Python zeigt die Struktur deutlich:
from pipecat.pipeline.pipeline import Pipeline
from pipecat.pipeline.runner import PipelineRunner
from pipecat.pipeline.task import PipelineTask
from pipecat.services.deepgram.stt import DeepgramSTTService
from pipecat.services.openai.llm import OpenAILLMService
from pipecat.services.elevenlabs.tts import ElevenLabsTTSService
from pipecat.transports.network.webrtc import WebRTCTransport
transport = WebRTCTransport(...)
stt = DeepgramSTTService(api_key="...")
llm = OpenAILLMService(model="gpt-4o", api_key="...")
tts = ElevenLabsTTSService(api_key="...", voice_id="...")
pipeline = Pipeline([
transport.input(), # InputAudioRawFrame → STT
stt, # TranscriptionFrame → LLM
llm, # LLMTextFrame → TTS
tts, # OutputAudioRawFrame → Transport
transport.output(),
])
runner = PipelineRunner()
task = PipelineTask(pipeline)
await runner.run(task)Jeder Prozessor empfängt Frames von seinem Vorgänger und sendet transformierte Frames an seinen Nachfolger. transport.input() liefert Rohaudiodaten, DeepgramSTTService gibt TranscriptionFrame-Objekte weiter, OpenAILLMService verarbeitet diese zu LLMTextFrame-Ausgaben, und ElevenLabsTTSService synthetisiert daraus Audiodaten für transport.output().
Diese Konstruktion entspricht dem Muster, das Forschungsarbeiten zu agentischen Sprach-KI-Pipelines als “cascaded architecture” beschreiben – mit dem wesentlichen Unterschied, dass die Lösung alle Übergänge intern managt und standardisierte Frame-Typen nutzt.
Transport-Ebene und Flows
Die sogenannten Flows sind ein Abstraktionsmechanismus über der Prozessebene: Sie erlauben die Definition von Gesprächs-Zustandsmaschinen, in denen der Agent je nach Kontext in verschiedene Zustände wechselt. Ein Customer-Service-Agent könnte beispielsweise von „Erstanfrage” zu „Authentifizierung” zu „Problemlösung” springen – ohne jedes Mal den Code neu zu initialisieren.
Der Transport-Layer abstrahiert die Verbindungsschicht vollständig. Das Signalisierungsprotokoll von WebRTC – normalerweise ein erheblicher Implementierungsaufwand – ist in dem Daily-Transport gekapselt. Entwickler konfigurieren einen DailyTransport mit Room-URL und Token; das interne System übernimmt ICE-Handshake, DTLS und SRTP.
Für Teams, die bereits n8n für Workflow-Automatisierung nutzen, ist die Konzeptübertragung naheliegend: Die Flows sind das Äquivalent zu bedingten Workflow-Verzweigungen – aber für Echtzeit-Audiodaten.
Interruption Handling bei Unterbrechung
Interruption Handling ist der zuverlässigste Indikator für Produktionsreife. Ein Sprachagent, der nach einer Nutzerunterbrechung weiter spricht, wirkt nicht wie ein Assistent – er wirkt wie ein Roboter.
Das System löst das Problem durch SystemFrame-Typen, die die normale Queue-Reihenfolge bypassen. Wenn ein neuer InputAudioRawFrame erkannt wird, während der TTS-Prozessor noch Ausgabe generiert, sendet die Engine einen CancelFrame – ein SystemFrame, der alle nachgelagerten Prozessoren sofort stoppt. Die neue Nutzereingabe wird dann als frischer Gesprächsbeginn verarbeitet.
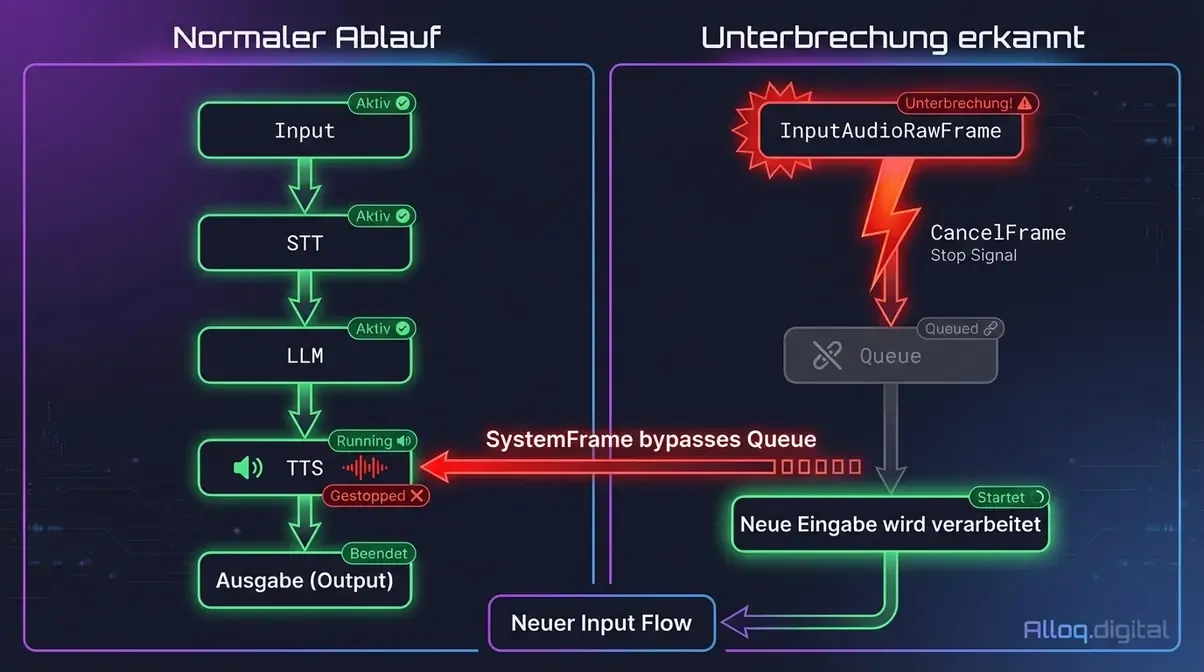 SystemFrames wie CancelFrame bypassen die normale Verarbeitungsqueue und stoppen aktive TTS-Ausgabe sofort - die Grundlage für natürliches Unterbrechungsverhalten.
SystemFrames wie CancelFrame bypassen die normale Verarbeitungsqueue und stoppen aktive TTS-Ausgabe sofort - die Grundlage für natürliches Unterbrechungsverhalten.
Caption: SystemFrames bypassen die normale Verarbeitungsqueue und ermöglichen sofortiges Stoppen aktiver TTS-Ausgabe.
Die Architektur bietet standardmäßig aktiviertes Interruption Handling über einen VADAnalyzer (Voice Activity Detection), der kontinuierlich Audiostreams auf Spracheinsätze überwacht. Das Ergebnis: natürliche Unterbrechungen ohne zusätzlichen Code.
Integrationen: React, Node.js & ESP32
Die Server-Logik allein ergibt noch kein Produkt. Sprach-KI-Agenten brauchen Clients – Browser-Apps, Mobile-Apps oder sogar Hardware-Geräte. Das Tool adressiert diesen Bedarf durch ein wachsendes Ökosystem von Client-SDKs, die alle das RTVI-Protokoll (Real-Time Voice and Video Inference) implementieren: einen einheitlichen Standard für Verbindung, Session-Management und Messaging zwischen Client und KI-Server.
Web: React, Node.js und TypeScript
Das JavaScript-Ökosystem wird durch zwei Pakete abgedeckt:
@pipecat-ai/client-js– Der JavaScript/TypeScript-Kern-SDK für Browser und Node.js. Er managt Media-Streams, Session-Lifecycle und RTVI-Messaging.@pipecat-ai/client-react– Ein React-spezifischer Wrapper mit vorgefertigten Hooks und Komponenten.
Ein minimales React-Setup:
import { PipecatClient, PipecatClientProvider, PipecatClientAudio } from '@pipecat-ai/client-react';
import { DailyTransport } from '@pipecat-ai/daily-transport';
const client = new PipecatClient({
transport: new DailyTransport(),
});
function VoiceAgent() {
return (
<PipecatClientProvider client={client}>
<PipecatClientAudio />
<button onClick={() => client.connect({ url: '/api/connect' })}>
Agent starten
</button>
</PipecatClientProvider>
);
}Die PipecatClientAudio-Komponente übernimmt das Audio-Rendering automatisch. Das TypeScript-Typsystem ist vollständig integriert: RTVI-Events wie bot-ready, user-started-speaking und bot-stopped-speaking sind typisiert und können in React-Hooks verarbeitet werden. Für Teams, die professionelle Webentwicklung umsetzen, reduziert das den Integrationsaufwand erheblich.
Edge-Computing auf dem ESP32
Das offizielle ESP32-SDK auf GitHub öffnet die Technologie für eine vollkommen andere Hardware-Klasse: kostengünstige Mikrocontroller für IoT- und Edge-Anwendungen. Der ESP32-S3, ein leistungsfähiger Dual-Core-Prozessor mit WLAN-Modul, fungiert dabei als Audio-Client, der mit einem Voice-Backend kommuniziert.
Das SDK wurde primär für den ESP32-S3 entwickelt und auf Linux getestet. Für erste Tests ohne Hardware kann das SDK auch auf Linux ausgeführt werden, ist dabei aber in der Funktionalität eingeschränkt.
Die Setup-Sequenz für den ESP32:
# 1. Repository klonen
git clone https://github.com/pipecat-ai/pipecat-esp32.git
cd pipecat-esp32
# 2. ESP-IDF-Pfad exportieren
export IDF_PATH=/path/to/esp-idf
# 3. WLAN-Zugangsdaten und Server-URL setzen
export WIFI_SSID="MeinNetz"
export WIFI_PASSWORD="MeinPasswort"
export PIPECAT_SMALLWEBRTC_URL="http://192.168.1.10:7860/api/offer"
# 4. Für ESP32-S3 bauen und flashen
idf.py set-target esp32s3
idf.py build flash monitorDer ESP32 verbindet sich via WebRTC (SmallWebRTCTransport). Das macht die Kombination besonders attraktiv für Szenarien wie smarte Sprachsteuerungen in eingebetteten Systemen, Fabrikboden-Assistenten ohne Display oder kostengünstige Prototyp-Hardware für Sprach-KI-Demos.
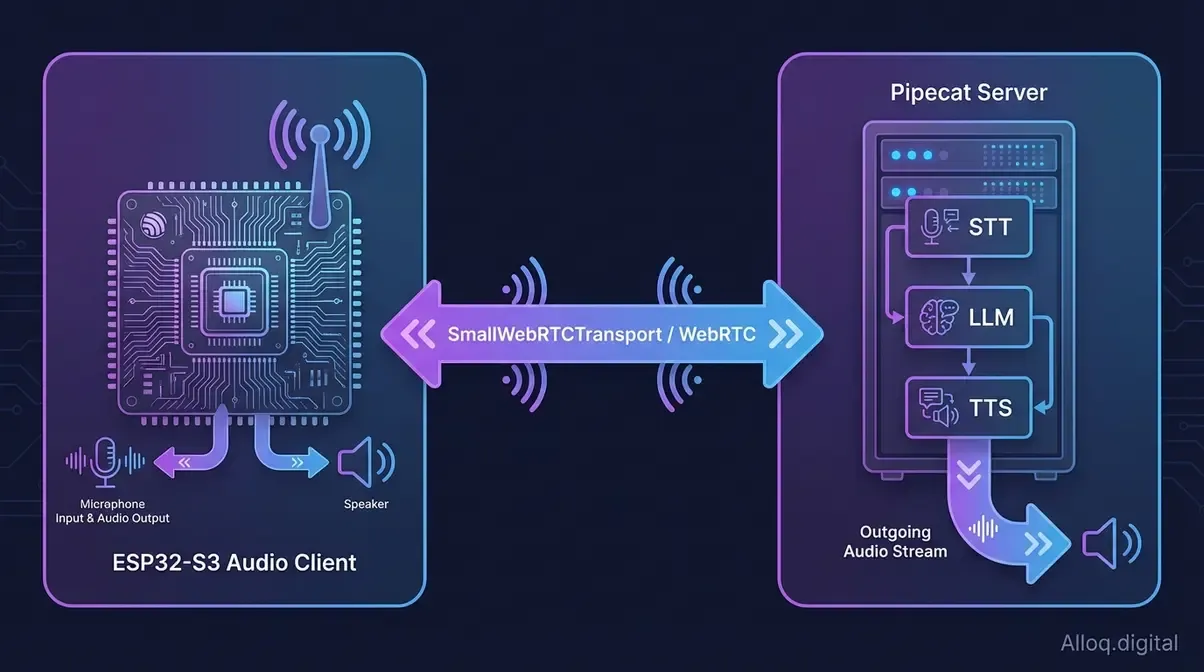 Der ESP32-S3 fungiert als schlanker Audio-Client: WebRTC-Verbindung via SmallWebRTCTransport bringt vollständige Pipecat-Sprach-KI auf Mikrocontroller-Hardware.
Der ESP32-S3 fungiert als schlanker Audio-Client: WebRTC-Verbindung via SmallWebRTCTransport bringt vollständige Pipecat-Sprach-KI auf Mikrocontroller-Hardware.
Caption: Der ESP32-S3 fungiert als Audio-Client – WebRTC-Verbindung zum Backend ermöglicht vollständige Sprach-KI auf Mikrocontroller-Hardware.
Client-SDKs und Amazon Nova Sonic
Über React und ESP32 hinaus bietet das Ökosystem SDKs für React Native (iOS/Android) und eine direkte Python-Client-Bibliothek. Alle nutzen dasselbe RTVI-Protokoll, was Portabilität zwischen Plattformen ohne Server-seitige Änderungen ermöglicht.
Erwähnenswert ist die Integration von Amazon Nova Sonic via Amazon Bedrock: Das native Sprachmodell von AWS für Sprach-zu-Sprach-Interaktion lässt sich direkt als LLM-Backend einsetzen und umgeht damit den separaten STT-TTS-Stack komplett – auf Kosten der Provider-Unabhängigkeit. Für Teams, die tief im AWS-Ökosystem arbeiten, kann das eine relevante Optimierung sein.
Ökosystem: Cloud, UI Kit und Docs
Daily.co, das Unternehmen hinter der Open-Source-Entwicklung, hat um den Kern ein vollständiges kommerzielles Ökosystem aufgebaut. Wer tiefer einsteigt, findet sowohl verwaltete Infrastruktur als auch vorgefertigte UI-Komponenten – beides eng mit der frei verfügbaren Basis verzahnt. Die Daily.co KI-Toolkit-Dokumentation gibt einen vollständigen Überblick.
Cloud-Hosting vs. Self-Hosting
Die Managed Cloud ist seit Januar 2026 allgemein verfügbar (Daily.co, 2026). Die Plattform ist bewusst vendor-neutral gestaltet: Code, der auf der Cloud-Plattform deployed wird, kann ohne Änderungen auch self-hosted betrieben werden. Vendor-Lock-in ist strukturell ausgeschlossen.
 Cloud-Hosting minimiert Setup-Aufwand und bietet automatische Skalierung - Self-Hosting liefert Kostenkontrolle und Datenhoheit bei stabilen Workloads.
Cloud-Hosting minimiert Setup-Aufwand und bietet automatische Skalierung - Self-Hosting liefert Kostenkontrolle und Datenhoheit bei stabilen Workloads.
Caption: Das Cloud-Hosting vereinfacht das Deployment erheblich – Self-Hosting bietet mehr Kontrolle bei niedrigeren Kosten für stabile Lastprofile.
| Merkmal | Cloud-Plattform | Self-Hosting (Docker) |
|---|---|---|
| Setup-Aufwand | Niedrig (CLI-Deployment) | Hoch (Infra-Management) |
| Skalierung | Automatisch (ARM-Container) | Manuell oder via Orchestrator |
| Agent-Start (P99) | < 1 Sekunde | Abhängig von Infrastruktur |
| Stand-by-Kosten | 1/20 der aktiven Kosten | Fixkosten (laufende Server) |
| Vendor-Abhängigkeit | Daily.co Billing | Keine |
| Monitoring | Eingebaut (Dashboard) | Eigene Lösung nötig |
| SOC-2-Compliance | Ja (Daily WebRTC-Infra) | Eigene Verantwortung |
Für Projekte in frühen Phasen oder mit unregelmäßigem Traffic bietet das verwaltete Hosting klare Vorteile: keine Infrastrukturkomplexität, automatisches Over-Provisioning bei Lastspitzen und P99-Agent-Startzeiten unter einer Sekunde. Self-Hosting lohnt sich vor allem bei stabilen, hochvolumigen Workloads, wo die Kostenstruktur vorhersehbar ist.
UI Kit und offizielle Dokumentation
Das begleitende UI Kit ist eine Sammlung vorgefertigter React-Komponenten für Voice-AI-Interfaces: Call-Controls, Transkriptions-Displays, Bot-Status-Indikatoren. Es baut direkt auf dem JavaScript-SDK auf und ist für shadcn/ui-Projekte konzipiert.
Die offizielle Dokumentation unter docs.pipecat.ai ist gut strukturiert und deckt alle Kernbereiche ab: Konzepte, Service-Integrationen, Client-SDKs, Cloud-Deployment. Nennenswert ist die große Sammlung an Beispielen im GitHub-Repository – von simplen Echo-Agenten bis zu vollständigen Customer-Service-Bots mit Flows und Tool-Calling.
Produktion: Deployment und Monitoring
Hier zeigt sich der Pipeline-Produktions-Gap am deutlichsten: Ein Quickstart-Demo läuft in 20 Minuten. Ein Produktionssystem, das unter Last stabil bleibt, Fehler graceful behandelt und auditierbar ist, erfordert eine andere Denkweise. Die Open-Source-Lösung liefert die Bausteine – aber der Entwickler muss sie gezielt einsetzen.
Deployment via Docker und Cloud
Für Self-Hosted-Deployments ist Docker der empfohlene Pfad. Diese Anwendungen sind Standard-Python-Apps und lassen sich problemlos containerisieren:
FROM python:3.11-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
EXPOSE 7860
CMD ["python", "bot.py"]Das Cloud CLI vereinfacht den Prozess erheblich – ohne lokale Docker-Installation oder Registry-Credentials:
# CLI installieren
pip install pipecatcloud
# Einloggen und Agent deployen
pipecat auth login
pipecat deploy --name mein-agentDer Deployment-Command baut das Image direkt in der Remote-Infrastruktur (Linux ARM) und deployt es ohne weiteres Zutun. Für Teams mit CI/CD-Pipelines existiert eine GitHub-Action (daily-co/pipecat-cloud-deploy-action), die das Deployment vollständig automatisiert.
Das NVIDIA Voice Agent Blueprint für Pipecat dokumentiert einen Referenz-Deployment-Stack für Enterprise-Szenarien: NVIDIA Build zeigt hier einen vollständigen Blueprint, wie GPU-beschleunigte Inferenz mit der Voice-Architektur kombiniert werden kann – relevant für Teams, die On-Premises-Infrastruktur mit hohen Latenzanforderungen betreiben. Für produktionsreife SaaS-Entwicklung mit Sprachagenten sind diese Deployment-Muster besonders relevant.
Monitoring und Performance-Analyse
Die Cloud-Umgebung bietet ein eingebautes Observability-Dashboard: Session-Transcripts, Latenz-Metriken pro Verarbeitungsschritt, Fehlerraten und Recording-Storage. Für Self-Hosted-Deployments ist die Kombination aus Prometheus (Metriken) und Grafana (Visualisierung) der Standard-Ansatz; die Plattform selbst exportiert grundlegende Timing-Informationen über Log-Ausgaben.
Ein kritischer Monitoring-Punkt in Produktionssystemen: die TTFB (Time To First Byte) des TTS-Dienstes. Da das Framework Streaming-TTS unterstützt, beginnt die Audioausgabe bereits, während das LLM noch generiert. Ein Monitoring-Setup sollte daher zwischen LLM-Start-Latenz, LLM-Token-Rate und TTS-TTFB differenzieren – nicht nur die Gesamtlatenz messen.
Vergleich: Framework vs. LiveKit
Der Vergleich zwischen der Lösung und LiveKit, einem alternativen Anbieter für Echtzeit-Kommunikation, ist in der Community einer der häufigsten Diskussionspunkte. Ein technischer Benchmark von Cekura.ai dokumentiert die wesentlichen Unterschiede.
 Pipecat gewinnt bei Provider-Flexibilität und Modularität - LiveKit liefert natives WebRTC mit leicht niedrigerer Baseline-Latenz für hochvolumige Szenarien.
Pipecat gewinnt bei Provider-Flexibilität und Modularität - LiveKit liefert natives WebRTC mit leicht niedrigerer Baseline-Latenz für hochvolumige Szenarien.
Caption: Beide Ansätze haben unterschiedliche Stärken – die Wahl hängt vom Prioritätsprofil des Projekts ab.
| Kriterium | Modulares Framework | LiveKit Agents |
|---|---|---|
| End-to-End-Latenz | 800–950 ms (Deepgram + GPT-4o + ElevenLabs) | 750–900 ms (gleicher Stack) |
| Transport | Daily WebRTC (primär) + WebSocket | Natives LiveKit WebRTC |
| Provider-Wechsel | Einfach (Prozessor-Austausch) | Mittlerer Aufwand |
| Interruption Handling | Nativ integriert | Nativ integriert |
| Self-Hosting | Docker + eigene Infra | Docker + eigene Infra |
| Verwaltetes Hosting | Daily.co Managed Cloud | LiveKit Cloud |
| Community | Wachsend (seit 2024) | Etabliert (seit 2021) |
| Stärke | Flexibilität, Provider-Unabhängigkeit | WebRTC-native Performance |
Der modulare Ansatz ist die bessere Wahl, wenn Provider-Austauschbarkeit und die freie Kombination von STT-, LLM- und TTS-Diensten im Vordergrund stehen. LiveKit gewinnt, wenn maximale WebRTC-Performance und minimale Latenz in hochvolumigen Szenarien entscheidend sind und das Team bereits LiveKit-Infrastruktur betreibt.
Das Latenz-Delta von 50–100 ms zugunsten von LiveKit ist in den meisten Consumer-Applikationen nicht wahrnehmbar, in Echtzeit-Übersetzungs- oder Trading-Szenarien jedoch relevant.
Einschränkungen und Alternativen
Das Tool ist ein starkes Konzept – aber kein universelles. Eine ehrliche Einschätzung der Grenzen hilft, den richtigen Einsatzbereich zu definieren und kostspielige Architekturfehler zu vermeiden.
Häufige Fallstricke in der Praxis
Fallstrick 1: Falsche Latenz-Erwartungen bei kaskadierter Architektur. Die beworbenen 500–800 ms Latenz gelten ausschließlich für optimierte Stacks mit Streaming-TTS und geografisch nahen API-Endpoints. Wer kostengünstige, nicht-streaming-fähige TTS-Dienste nutzt, kann schnell 1.500–2.000 ms End-to-End-Latenz erleben – weit außerhalb des Bereichs natürlicher Konversation.
Fallstrick 2: Frame-Typen-Fehler bei eigenen Prozessoren. Entwickler, die eigene FrameProcessor-Subklassen implementieren, müssen sicherstellen, dass alle Frame-Typen korrekt an nachgelagerte Prozessoren weitergeleitet werden. Andernfalls kommt es zu stillen Ausfällen, bei denen Frames einfach verschwinden. Die Lösung: Die Eigenschaft passthrough_frames explizit konfigurieren.
Fallstrick 3: Synchrone Operationen in async-Pipelines. Die Architektur ist absolut async-native. Blockierende Datenbankabfragen oder synchrone HTTP-Calls in einem FrameProcessor blockieren sofort die gesamte Pipeline-Verarbeitung. Konsequentes asyncio (oder httpx für HTTP) ist hier zwingend Pflicht.
Wann LiveKit sinnvoller ist
LiveKit ist die bessere Wahl, wenn das Team bereits LiveKit-Infrastruktur für Video-Conferencing betreibt und diese Bibliothek als zweites Framework zu viel Komplexität in den Technologie-Stack einführen würde. LiveKit profitiert von einer nativen WebRTC-Infrastruktur, die für extrem niedrige Latenzen in Voice-Applikationen optimiert ist. Die Latenzvorteile von 50–100 ms machen sich in hochskalierbaren Szenarien bemerkbar. Vollständig verwaltete Plattformen wie Retell AI oder VAPI bieten sich hingegen an, wenn Entwickler keine eigene Infrastruktur aufsetzen möchten und eine schlüsselfertige Out-of-the-Box-Lösung bevorzugen.
Häufig gestellte Fragen (FAQ)
Was ist der Unterschied zwischen der hier vorgestellten Pipeline und LiveKit? Der Hauptunterschied liegt in der Architektur und Provider-Bindung. Während LiveKit eine native WebRTC-Infrastruktur für Video- und Audiodaten mit hochintegrierten Agenten nutzt, fungiert die Open-Source-Alternative primär als neutraler Orchestrator verschiedener KI-Modelle. Letztere Option ermöglicht den nahtlosen und schnellen Austausch einzelner Dienste (wie LLMs oder STT). LiveKit liegt hingegen bei reinen Latenz-Benchmarks oft leicht vorne, weshalb hochgradig anpassbare Projekte eher den modularen Weg gehen sollten.
Ist das Framework für den produktiven Einsatz geeignet? Ja, die Lösung wird nachweislich von über 1.000 Entwickler-Teams in Produktionsumgebungen erfolgreich eingesetzt. Durch das fest eingebaute Interruption Handling, robustes Queue-Management und dedizierte System-Frames für Unterbrechungen meistert sie typische Skalierungsprobleme souverän. Die Ausfallsicherheit auf Enterprise-Niveau hängt jedoch maßgeblich von einer sauberen asynchronen Implementierung des eigenen Codes ab.
Wie hoch ist die Latenz bei diesen Sprachagenten? In einem optimierten Setup mit geografisch nahen API-Endpoints (wie Deepgram und OpenAI) liegt die End-to-End-Latenz typischerweise zwischen 500 und 800 Millisekunden. Diese Reaktionszeit ermöglicht natürliche, flüssige Konversationen ohne störende Pausen zwischen Sprecher und Bot. Laut dem Benchmark von Cekura.ai kann bei der Wahl von nicht-streamingfähigen Text-to-Speech-Diensten die Verzögerung jedoch schnell auf über 1.500 Millisekunden ansteigen.
Kann ich die Pipeline lokal ohne Cloud-Kosten hosten? Das Framework ist vollständig quelloffen und unter der BSD-3-Clause-Lizenz freigegeben, wodurch ein komplett lokales Hosting via Docker auf eigenen Servern problemlos möglich ist. Dadurch fallen keine Lizenzgebühren für die Architektur an, sondern lediglich die reinen API-Kosten der extern angebundenen Sprachmodelle. Wer Hardware-Kosten radikal sparen will, kann die schlanke Infrastruktur sogar auf einem kostengünstigen ESP32-Mikrocontroller am Edge betreiben.
Welche Sprachen und LLMs unterstützt das System? Da das Tool als völlig neutrale Middleware agiert, unterstützt es alle Sprachen, die von den angeschlossenen Providern angeboten werden. Es existieren native Integrationen für OpenAI, Anthropic, Google Gemini und Amazon Bedrock, wodurch Entwickler das leistungsfähigste Modell für ihren spezifischen Markt auswählen können. Wenn ein Sprachmodell speziell auf die deutsche Sprache optimiert ist, leitet die Architektur diese Fähigkeiten ohne jegliche Qualitätsverluste direkt an den Nutzer weiter.
Fazit
Der Pipeline-Produktions-Gap stellt für viele Entwicklungsteams die größte Hürde bei der Bereitstellung von Echtzeit-Sprach-KI dar. Das hier detailliert analysierte Open-Source-Framework schließt diese Lücke effektiv, indem es robuste asynchrone Architekturmuster mit maximaler Provider-Unabhängigkeit kombiniert. 750–900 ms End-to-End-Latenz in optimierten Stacks beweisen, dass modulare Flexibilität nicht zwingend auf Kosten der Echtzeitfähigkeit gehen muss.
Mit standardisierten Frame-Typen, sicherem Interruption Handling und einer sauberen Trennung von Transport- und Logik-Ebene erhalten Ingenieure ein mächtiges Werkzeug. Im Gegensatz zu vollständig verwalteten Blackbox-Lösungen behalten Sie so die absolute Kontrolle über Latenzschwellen, Betriebskosten und die sensiblen Datenströme.
Wenn Sie Unterstützung bei der strategischen Planung oder der technischen Implementierung komplexer KI-Systeme benötigen, werfen Sie einen Blick auf unsere KI-Agenten-Entwicklung mit Voice-Integration. Unser Entwicklungsteam hilft Ihnen dabei, vielversprechende Prototypen in ausfallsichere, latenzoptimierte Produktionsumgebungen zu überführen.