Entwickler, die zum ersten Mal mit semantischer Suche arbeiten, beschreiben Vektordatenbanken gelegentlich als „widerspenstiges Biest” - ein System, das sich grundlegend anders verhält als alles, was man aus SQL oder MongoDB kennt. Das Bild ist treffend. Vektordatenbanken folgen keiner Zeilenlogik, keiner Schemavalidierung und keiner deterministischen Ausgabe. Sie operieren im hochdimensionalen Raum, suchen nach Annäherungen statt Exakttreffer und entscheiden über Architekturentscheidungen, die sich tief in Produktionskosten niederschlagen.
Genau deshalb lohnt es sich, diese Infrastrukturkomponente methodisch zu verstehen - nicht nur, welche API-Endpunkte Pinecone bereitstellt, sondern warum HNSW-Indizes so gebaut sind, wie sie gebaut sind, was der Recall-Kosten-Kompromiss für Ihre Servicevereinbarungen bedeutet und wann pgvector eine valide Alternative zu einem dedizierten Vector Store ist. Eine leistungsfähige vector datenbank ist längst keine akademische Spielerei mehr, sondern ein operatives Muss. Dieser Guide beantwortet genau das: von der Embedding-Theorie bis zum konkreten Anbietervergleich mit aktuellen Preisdaten.
Key Takeaways (Der Recall-Kosten-Kompromiss)
Vektordatenbanken sind die Kerndatenstruktur für RAG-Systeme und semantische Suche - sie speichern hochdimensionale Embeddings und finden ähnliche Inhalte ohne Keyword-Treffer.
- Semantische Suche: HNSW-Indizes erzielen bei Millionen von Vektoren 95–99 % Recall bei Latenzen unter 2 ms (ANN-Benchmarks, 2026).
- Der Recall-Kosten-Kompromiss: Höhere Suchgenauigkeit steigert Rechenkosten exponentiell - dieser Trade-off bestimmt die Tool-Wahl.
- RAG-Markt: Der globale Markt erreicht rund 2,76 Mrd. USD und wächst mit 49 % CAGR (Precedence Research, 2026) - dies zwingt IT-Abteilungen zu massiven Investitionen in skalierbare Retrieval-Systeme.
- Kostenrealität: Bei 10 Mio. Vektoren kostet Pinecone ~70 $/Monat (Serverless), pgvector auf RDS ~45 $/Monat.
- Kritischer Flaschenhals: Embedding-Qualität und Chunk-Strategie bestimmen die tatsächliche Suchpräzision im Produktionsbetrieb.
Was ist eine Vektordatenbank?
Vektordatenbanken transformieren unstrukturiertes Unternehmenswissen in durchsuchbare mathematische Räume. Diese hochspezialisierten Systeme überwinden die Limitierungen klassischer relationaler Architekturen, indem sie semantische Bedeutungen statt exakter Zeichenketten indexieren. Entwickler nutzen diese Datenbanken als fundamentales Fundament für Retrieval-Augmented Generation (RAG), da herkömmliche Keyword-Suchen bei kontextbezogenen Benutzeranfragen systematisch scheitern.
Ein wesentlicher Vorteil besteht darin, dass diese Datenstrukturen natürliche Sprachmuster verstehen. Anders als relationale Datenbanken, die exakte Token abrufen, sucht ein solches System nach dem semantisch nächstgelegenen Nachbarn in einem multidimensionalen Koordinatensystem. Dieses Prinzip macht sie zur unverzichtbaren Infrastruktur für moderne Multimodal-KI-Systeme. Meiner Einschätzung nach wird in wenigen Jahren jedes Enterprise-System, das unstrukturierte Daten verarbeitet, zwingend auf einer Vektor-Engine basieren.
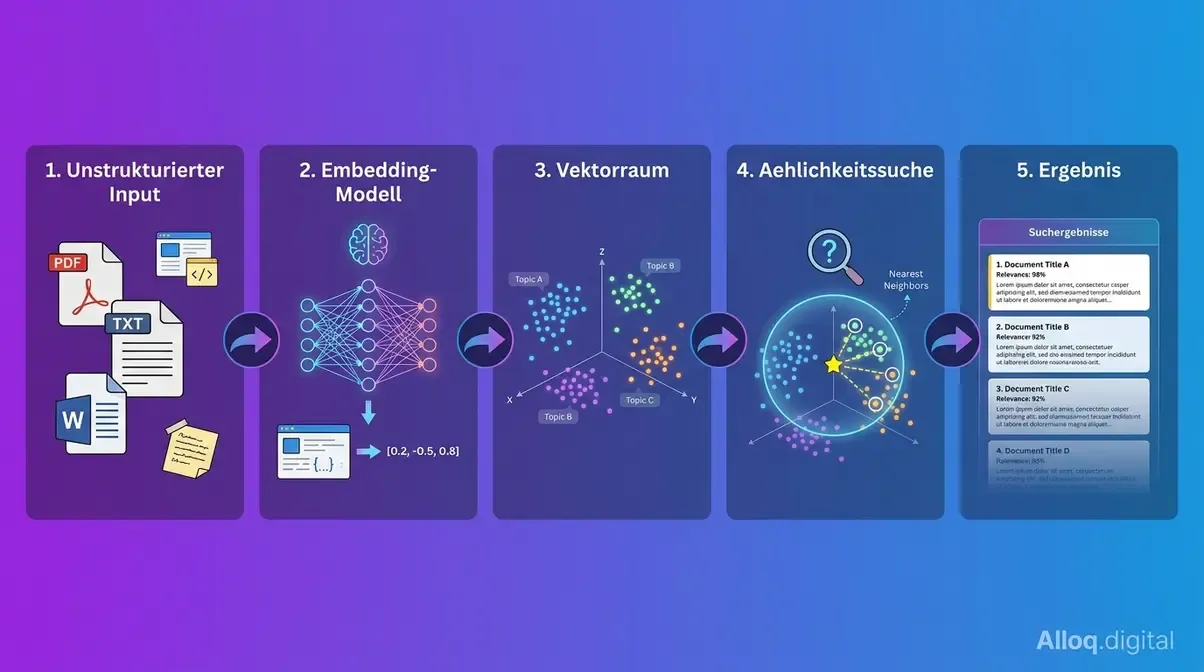 Der vollstaendige Datenpfad einer Vektordatenbank - vom Rohtext ueber das Embedding-Modell bis zur semantischen Suchanfrage in fuenf Schritten.
Der vollstaendige Datenpfad einer Vektordatenbank - vom Rohtext ueber das Embedding-Modell bis zur semantischen Suchanfrage in fuenf Schritten.
Caption: Der vollständige Datenpfad einer Vektordatenbank - vom Rohtext über das Embedding-Modell bis zur semantischen Suchanfrage.
Embeddings & Vektoren
Ein Embedding ist die numerische Darstellung eines Objekts - ob Textzeile, Bilddatei, Audiospur oder Codeblock - als exakter Punkt in einem hochdimensionalen Vektorraum. Moderne Textmodelle erzeugen typischerweise Vektoren mit 768 bis 1.536 Dimensionen. Jede dieser Dimensionen codiert eine latente semantische Eigenschaft der Ursprungsdaten.
Das bedeutet in der Praxis: Semantisch ähnliche Inhalte wie „Hund” und „Tier” oder „Rechnung stornieren” und „Bestellung zurückgeben” liegen in diesem Vektorraum geometrisch nah beieinander, obwohl sie lexikalisch oft keinerlei Zeichenüberlappung aufweisen. Moderne Text-Embeddings nutzen oft 1.536 Dimensionen - diese enorme mathematische Tiefe ermöglicht erst das präzise Verständnis feiner semantischer Nuancen in komplexen Unternehmensdaten.
Entscheidend ist, dass dieses räumliche Nähe-Konzept vollständig von der Qualität des initialen Embedding-Modells abhängt. Eine Forschungsarbeit von arXiv (2026) belegt: Selbst erstklassige Embedding-Modelle scheitern an fundamentalen theoretischen Grenzen, wenn die Dimensionalität für den spezifischen Use Case nicht ausreicht. Die Dimensionsanzahl bestimmt die maximale Kapazität unterscheidbarer Dokument-Subsets im Korpus.
Unstrukturierte Daten umwandeln
Der technische Prozess beginnt stets mit einem Embedding-Modell, beispielsweise text-embedding-3-large von OpenAI, multilingual-e5-large von Microsoft oder stark domänenspezifischen Modellen wie jina-embeddings-v3. Dieses Modell nimmt den Rohtext als Input entgegen und produziert am Ende einen Floating-Point-Vektor mit einer vordefinierten, festen Dimension. Dieser Vektor wird anschließend zusammen mit relevanten Metadaten wie Quelle, Zeitstempel und Chunk-ID in der Vektordatenbank dauerhaft persistiert.
Die kritischste Designentscheidung in dieser Pipeline liegt im Chunking-Verfahren. Zu kleine Chunks (unter 128 Token) verlieren ihren essenziellen semantischen Kontext. Zu große Chunks (über 1.024 Token) verdünnen das thematische Signal zu stark. Das naive, gleich große Abschneiden von Texten nach fixer Zeichenanzahl zerstört semantische Zusammenhänge an wichtigen Satzgrenzen - ein fataler Produktionsfehler, der später durch keine Indexoptimierung mehr korrigierbar ist. Semantisches Chunking ist hierbei immer überlegen.
Arten von Vektordaten
Vektordatenbanken sind keineswegs ausschließlich auf Textdokumente beschränkt. In der Industrie dominieren derzeit drei Hauptkategorien für den Produktionseinsatz, die jeweils eigene Vor- und Nachteile mit sich bringen:
- Dense Vectors (Dichte Vektoren): Jede einzelne Dimension des Arrays trägt numerische Informationen ungleich Null. Dies ist typisch für komplexe semantische Text- und Bildrepräsentationen und der Standard für die meisten gängigen RAG-Anwendungen.
- Sparse Vectors (Dünne Vektoren): Die überwiegende Mehrheit der Dimensionen ist genau Null, analog zu klassischen TF-IDF-Repräsentationen. Sie sind massiv effizienter bei spezifischen lexikalischen Inhalten wie Produktcodes oder rechtlichen Aktenzeichen.
- Multimodale Vektoren: Text, Bild und Audio werden in einem identischen, gemeinsamen Einbettungsraum projiziert. Dies ist höchst relevant für moderne Anwendungen wie Bild-zu-Text-Suchen.
Modernes Hybrid-Search kombiniert Dense und Sparse Vectors in einer einzigen Abfrage, um sowohl semantische als auch exakte lexikalische Treffer gleichzeitig zu erzielen. Das offizielle Microsoft Learn Portal dokumentiert diesen hybriden Ansatz mittlerweile als Standardmuster in skalierbaren Enterprise-Vektorarchitekturen.
Wie Vektordatenbanken wirklich funktionieren
HNSW-Algorithmen dominieren die moderne semantische Suche durch ihre überlegene Balance aus Geschwindigkeit und Genauigkeit. Diese graphenbasierten Indexstrukturen navigieren effizient durch Millionen von hochdimensionalen Vektoren, um den am nächsten gelegenen Nachbarn in Millisekunden zu identifizieren. Architekten müssen bei der Implementierung jedoch die extremen Arbeitsspeicheranforderungen berücksichtigen, da der vollständige Graph für eine verzögerungsfreie Abfrage im RAM vorgehalten werden muss.
Wenn Sie verstehen wollen, warum eine Produktions-Datenbank manchmal absolut relevante Dokumente verpasst, müssen Sie zwingend drei Architekturschichten kennen: die zugrundeliegende Ähnlichkeitsmetrik, den Indexierungsalgorithmus und die Spannungsfelder zwischen beiden. Diese Schichten definieren gemeinsam den berüchtigten Recall-Kosten-Kompromiss. Aus meiner Sicht ist die Ignoranz gegenüber diesem Trade-off der Hauptgrund für scheiternde RAG-Projekte in Großunternehmen.
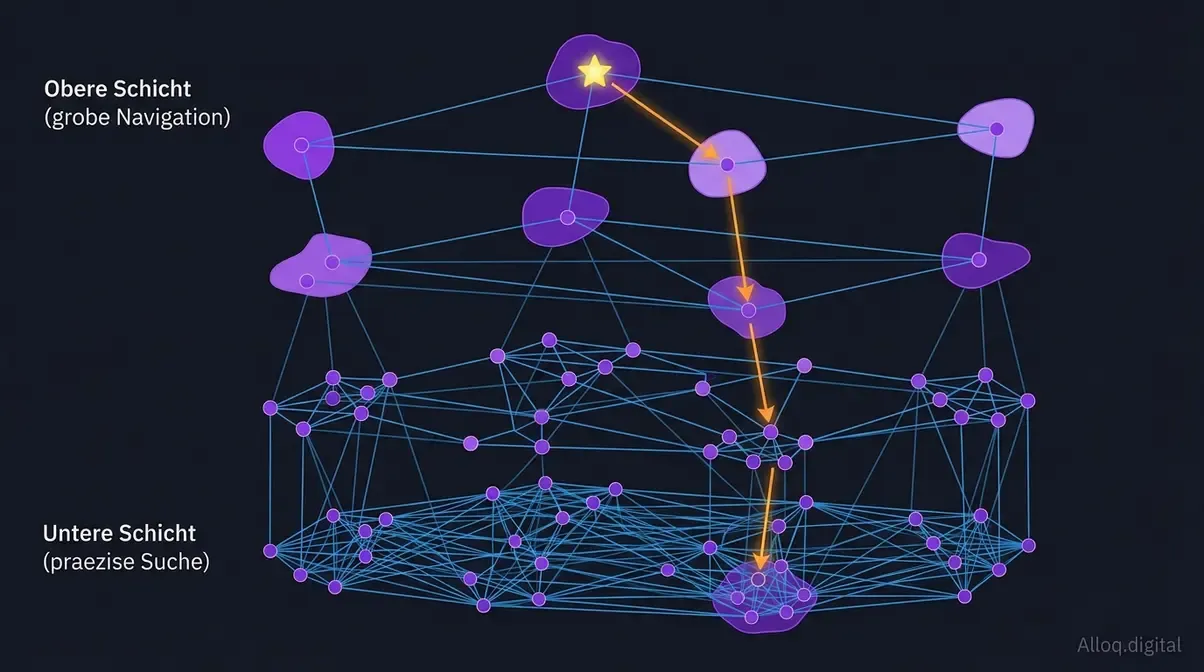 HNSW-Architektur im Detail: Hierarchische Schichten ermoeglichen Suchlatenzen unter 2 ms durch progressive Annaeherung vom groben zum praezisen Navigations-Graph.
HNSW-Architektur im Detail: Hierarchische Schichten ermoeglichen Suchlatenzen unter 2 ms durch progressive Annaeherung vom groben zum praezisen Navigations-Graph.
Semantik statt Keyword-Matching
Klassische Suchdatenbanken wie Elasticsearch oder die PostgreSQL Full-Text-Suche operieren primär auf sogenannten invertierten Indizes. Sie suchen nach exakt den gleichen Tokens im Dokument. Eine Suchanfrage nach dem String „Kündigung Mobilfunkvertrag” findet Dokumente mit exakt diesen Wörtern, ignoriert aber völlig Texte, die inhaltlich identisch „Vertrag beenden” oder „SIM-Karte abmelden” formulieren.
Semantische Suche löst genau dieses Problem durch Vektornähe elegant auf. Die Nutzeranfrage wird in denselben Embedding-Raum projiziert wie die bereits gespeicherten Firmendokumente. Das Datenbanksystem berechnet anschließend, welche gespeicherten Vektoren dem neuen Anfragevektor mathematisch am ähnlichsten sind. Das Ergebnis ist eine systemübergreifend wesentlich konsistentere Antwortsqualität.
Der praktische Nachteil dieser Methode: Exakte Fachbegriffe, spezifische Produktnummern, Gesetzesreferenzen oder seltene Eigennamen werden in der reinen Vektorsuche sehr oft übersehen. Hybride Systeme, die Vektorsuche strikt mit traditionellem Keyword-Filtering (BM25) kombinieren, bilden deshalb in Produktionsumgebungen den absolut empfohlenen Branchenstandard.
Distanzmetriken im Detail
Drei zentrale Distanzmetriken dominieren den globalen Praxiseinsatz von Vektorsystemen. Die Wahl der Metrik ist keineswegs beliebig und entscheidet über die Korrektheit der Retrieval-Logik. Kosinus-Ähnlichkeit ist die Standardwahl für Textembeddings, weil sie reine Richtungsunterschiede im Vektorraum misst.
- Kosinus-Ähnlichkeit: Misst den Winkel zwischen zwei Vektoren, völlig unabhängig von ihrer absoluten Länge. Ideal für NLP und RAG-Pipelines.
- Euklidische Distanz: Misst die direkte räumliche Entfernung (Luftlinie) zwischen zwei Vektorpunkten. Skaliert oft schlecht mit extremen Dimensionen, taugt aber für Bildsuche.
- Dot Product: Ein schnelles Skalarprodukt, das sowohl Richtung als auch Magnitude stark berücksichtigt. Perfekt für hochperformante Empfehlungssysteme.
Richtung trägt die semantische Information, nicht die Magnitude. Die Technische Universität München bestätigt dieses Modell in ihrer Forschung zur hochdimensionalen Datenverarbeitung als mathematisch fundiert für strikt normalisierte Einbettungsräume.
HNSW & ANN-Algorithmen
Das absolute Herzstück jeder Vektordatenbank ist der Approximate Nearest Neighbor (ANN) Algorithmus. Eine exakte Nearest-Neighbor-Suche (k-NN) skaliert linear mit der Datenmenge, was bei Millionen von Vektoren zu Latenzen im Sekundenbereich führt und schlichtweg inakzeptabel ist. ANN-Algorithmen akzeptieren bewusst einen minimal definierten Recall-Verlust, um Latenzen im Millisekundenbereich zu erzwingen.
HNSW (Hierarchical Navigable Small World) ist heute der unangefochtene De-facto-Standard für hochdimensionale Vektoren. HNSW-Indizes reduzieren Suchlatenzen auf unter 2 Millisekunden - dieser signifikante Geschwindigkeitsvorteil erfordert jedoch den architektonischen Kompromiss eines massiv erhöhten Arbeitsspeicherbedarfs. Die Parameter M und efConstruction bestimmen beim Indexaufbau die Dichte der Graphenvernetzung.
Genau hier manifestiert sich der Recall-Kosten-Kompromiss: Mehr Recall kostet zwingend wertvolle CPU-Zyklen, Unmengen an RAM und Suchlatenz. Die Purdue University analysiert in ihrer Forschung zu ANN-Algorithmen ausführlich, dass die Wahl zwischen Recall-Maximierung und Latenz-Minimierung immer strikt systemspezifisch kalibriert werden muss.
Zugriff & Sicherheit
Embeddings sind keine undurchdringlichen, opaken Blobs. Jüngste Forschungsergebnisse zeigen alarmierend, dass Vektoren theoretisch zurück in einen approximativen Klartext invertierbar sind - ein in Unternehmensumgebungen noch immer regelmäßig extrem unterschätztes Sicherheitsrisiko. Produktionsarchitekturen erfordern daher zwingende Härtungsmaßnahmen.
Mandantenfähigkeit ist essenziell. Moderne Systeme wie Qdrant oder Pinecone bieten Namespace-basierte Isolationstrennungen für Multi-Tenant-Systeme nativ an. Zusätzlich ist eine granulare Zugriffskontrolle (RBAC) auf der strikten Ebene einzelner Collections unerlässlich, ebenso wie lückenlose Audit-Logs für sämtliche Datenzugriffe, um kritische DSGVO-Anforderungen beim Speichern personenbezogener Embeddings dauerhaft zu erfüllen.
Vektordatenbank vs. SQL, NoSQL & Graphen-DB
Graphendatenbanken übertreffen traditionelle Vektorsysteme bei hochkomplexen Multi-Hop-Abfragen, bei denen logische Beziehungen zwischen Entitäten im Fokus stehen. Diese netzwerkorientierten Architekturen garantieren eine präzise Traversierung von Abhängigkeiten, während reine Vektordatenbanken auf unstrukturierte Ähnlichkeitssuchen spezialisiert bleiben. Hybride Lösungsansätze vereinen mittlerweile beide Welten, um Enterprise-KI-Anwendungen mit semantischer Flexibilität und relationaler Strenge gleichzeitig auszustatten.
Die Frage „Brauche ich wirklich eine dedizierte Vektordatenbank?” ist architektonisch weitaus ernster zu nehmen, als Hype-getriebene Tool-Evaluierungen oft suggerieren. Die ehrliche Antwort lautet: Für viele Basis-Anwendungsfälle reicht eine Extension wie pgvector oder ein clever konfigurierter Elasticsearch-Cluster völlig aus. Der fundamentale Unterschied liegt im spezifischen Retrieval-Muster. Ich rate Teams generell dazu, erst dann auf reine Vektorsysteme zu migrieren, wenn die Hardwarekosten für das bestehende System unrentabel werden.
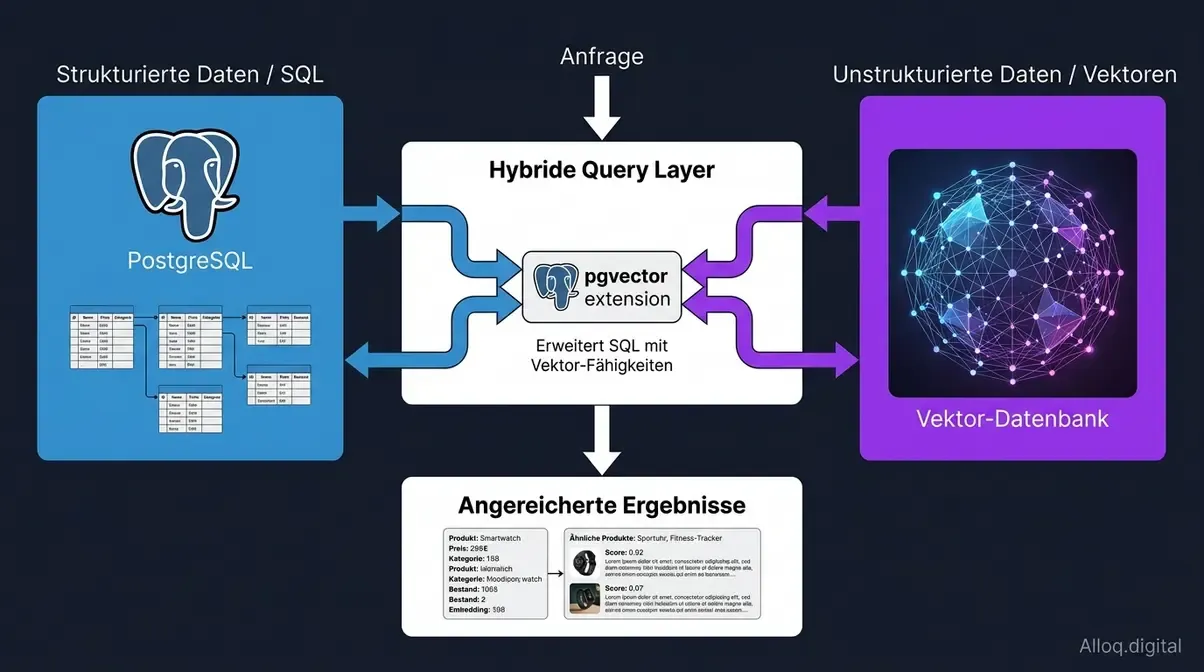 Hybride Architektur: Vektorsuche und SQL-Abfragen werden im Query-Layer kombiniert - der Branchenstandard fuer Enterprise-Produktionsumgebungen.
Hybride Architektur: Vektorsuche und SQL-Abfragen werden im Query-Layer kombiniert - der Branchenstandard fuer Enterprise-Produktionsumgebungen.
Relationale vs. Vektordatenbank
Relationale Datenbanken wie PostgreSQL oder MySQL wurden historisch für streng strukturierte Daten, harte transaktionale ACID-Konsistenz und exakte SQL-Abfragen hochoptimiert. Ihre B-Tree-Indizes sind schlichtweg unschlagbar, wenn es um exakte Primärschlüssel-Lookups, enge Bereichsabfragen und komplexe JOIN-Operationen über dutzende Tabellenstrukturen geht.
Sobald die technische Frage jedoch lautet „Welche Dokumente sind semantisch stark ähnlich zu dieser spezifischen Freitextanfrage?”, stoßen diese relationalen Systeme fundamental an ihre mathematischen Grenzen. Es gibt in SQL kein natives Datenbankprimitiv für Vektornähe. Erweiterungen wie pgvector schließen diese schmerzhafte Lücke, jedoch oft mit messbaren Performanceeinbußen gegenüber nativen C++ oder Rust Vektor-Engines.
NoSQL & Graphendatenbanken
NoSQL-Datenbanken (beispielsweise MongoDB oder Cassandra) optimieren strikt für horizontale Skalierung, enorme Schreiblasten und extrem flexible Schemata. MongoDB hat kürzlich Vector Search als natives Feature ergänzt, jedoch bleibt der Ansatz oft eine nachträgliche Rüstung und keine von Grund auf vector-native Speicherarchitektur. Bei parallelen Abfragen auf dutzenden Millionen Vektoren zeigen sich schnell Limitierungen.
Graphendatenbanken wie Neo4j modellieren relationale Netzwerke ideal für komplexe Wissensgraphen. Graphendatenbanken erzielen bei Multi-Hop-Abfragen über 90 Prozent Genauigkeit - Vektorsysteme dominieren stattdessen mit 7-Millisekunden-Latenz bei reinen semantischen Ähnlichkeitssuchen für unstrukturierte Texte. Externe Benchmarks zeigen, dass GraphRAG (die Verknüpfung von Graphen mit RAG) Wissensinseln besser verbindet, aber bei isolierten Retrieval-Aufgaben deutlich langsamer agiert als Pinecone oder Milvus.
pgvector: PostgreSQL-Hybride
Die Extension pgvector ist die mit Abstand pragmatischste Einstiegsoption für Entwicklungsteams, die ohnehin bereits robuste PostgreSQL-Cluster betreiben. Als native Extension fügt sie mächtige Indextypen wie HNSW, IVFFlat und Flat hinzu, unterstützt Kosinus-Ähnlichkeit fehlerfrei und läuft vollständig sicher innerhalb des vertrauten PostgreSQL-Transaktionskontexts.
-- pgvector: Extension aktivieren und hybride Tabelle erstellen
CREATE EXTENSION IF NOT EXISTS vector;
CREATE TABLE dokumente (
id SERIAL PRIMARY KEY,
inhalt TEXT,
embedding vector(1536) -- OpenAI text-embedding-3-large Dimensionierung
);
-- HNSW-Index für performante semantische Ähnlichkeitssuche anlegen
CREATE INDEX ON dokumente USING hnsw (embedding vector_cosine_ops);
-- Suche nach den 5 semantisch ähnlichsten Dokumenten im Bestand
SELECT inhalt, 1 - (embedding <=> '[0.1, 0.2, ...]') AS ähnlichkeit
FROM dokumente
ORDER BY embedding <=> '[0.1, 0.2, ...]'
LIMIT 5;Der architektonische Kompromiss liegt im Skalierungsverhalten: pgvector skaliert hervorragend bis etwa 5 Millionen Vektoren bei moderaten Query-Throughput-Anforderungen. Bei extremeren Lasten stoßen Architektur und Speichermodell spürbar an ihre Grenzen. Unsere Supabase-Analyse zeigt detailliert, wie sich pgvector im Managed-PostgreSQL-Umfeld in der harten Produktionspraxis verhält.
RAG: Vektordatenbanken als KI-Gedächtnis
Retrieval-Augmented Generation (RAG) koppelt große Sprachmodelle dynamisch an externe Wissensspeicher, um Halluzinationen in produktiven KI-Anwendungen zu eliminieren. Diese Architektur integriert die Vektordatenbank als operatives Langzeitgedächtnis, welches relevante Kontextinformationen in Echtzeit an den Prompt übergibt. Enterprise-Teams reduzieren durch diesen Ansatz die Abhängigkeit von teuren Fine-Tuning-Prozessen erheblich und gewährleisten gleichzeitig die kryptografische Sicherheit proprietärer Firmendaten.
Der RAG-Markt explodiert förmlich in der Adaption. RAG-Budgets wachsen laut Prognosen jährlich um 49 Prozent - die zugrundeliegende vector datenbank entscheidet hierbei zwingend über Latenz und Antwortpräzision des Gesamtsystems. Unternehmen jeder Größe bauen gerade massiv eigene Retrieval-Infrastruktur auf. Der Treiber ist das Problem großer Modelle: GPT-4 weiß zwar alles über das Internet, aber absolut nichts über Ihre aktuellen internen Kundendaten. Meine Erfahrung zeigt, dass RAG dieses Defizit am elegantesten und kosteneffizientesten löst.
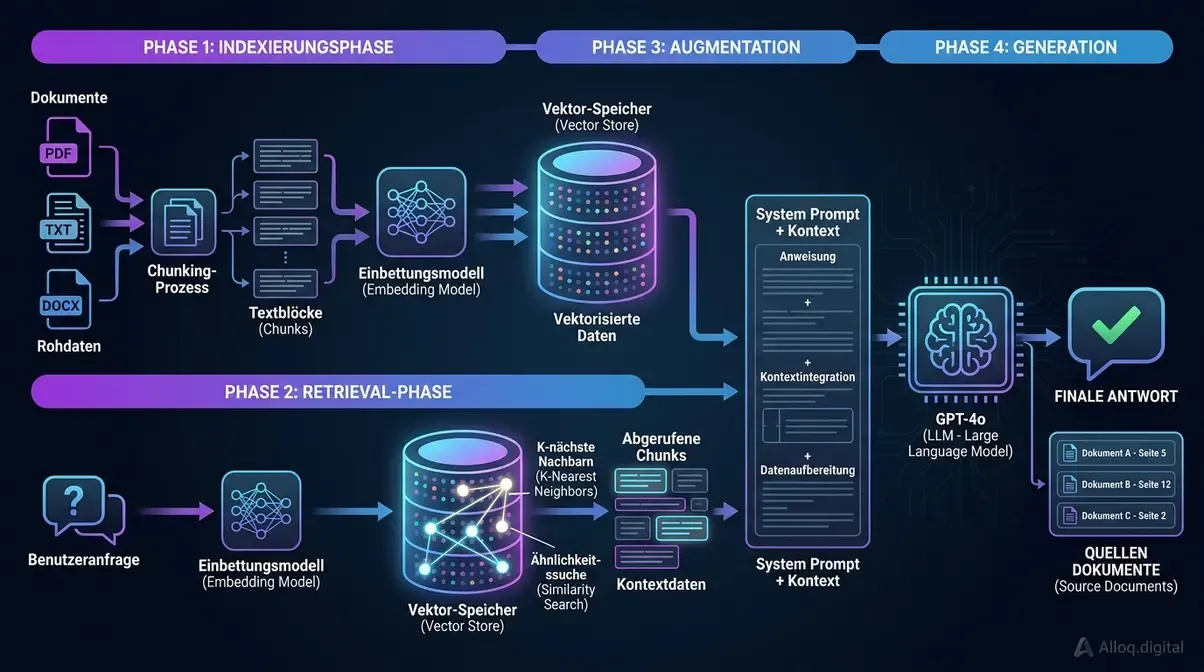 Der vollstaendige RAG-Ablauf in vier klar getrennten Phasen: Indexierung, Retrieval, Augmentation und Generation - das Architekturmuster, das LLM-Halluzinationen eliminiert.
Der vollstaendige RAG-Ablauf in vier klar getrennten Phasen: Indexierung, Retrieval, Augmentation und Generation - das Architekturmuster, das LLM-Halluzinationen eliminiert.
Der RAG-Ablauf im Detail
Die RAG-Methodik ist ein Architekturmuster, das ein generatives LLM stabil an einen extern verifizierten Wissensspeicher bindet. Der Ablauf vollzieht sich in vier streng getrennten Phasen.
- Indexierungsphase: Dokumente werden in Chunks aufgeteilt, durch Embedding-Modelle vektorisiert und gespeichert.
- Retrieval-Phase: Nutzeranfragen werden eingebettet und die Vektordatenbank gibt die K ähnlichsten Chunks blitzschnell zurück.
- Augmentation: Diese Chunks werden als verifizierter Hard-Fact-Kontext hart in den System-Prompt des LLMs injiziert.
- Generation: Das LLM formuliert eine finale Antwort, die ausschließlich auf den abgerufenen Dokumenten basiert.
Fraunhofer IESE untersucht RAG-Architekturen intensiv als Kernmuster für Enterprise-Systeme und betont nachdrücklich die überragende Bedeutung vollständig kontrollierter Retrieval-Pipelines für stark Compliance-relevante Industrieanwendungen.
Enterprise-Anwendungsfälle
Vektordatenbanken fungieren als dediziertes RAG-Backend und decken dabei eine extrem breite Palette stark unternehmensrelevanter Szenarien hochgradig zuverlässig ab:
- Interne Wissensdatenbanken: Ein interner KI-Bot beantwortet Mitarbeiterfragen zu HR-Richtlinien basierend auf tatsächlichen PDF-Handbüchern. Fraunhofer IWU demonstriert dies im produktionstechnischen Wissensmanagement sehr erfolgreich.
- Semantische Produktsuche: E-Commerce-Plattformen finden Produkte durch natürliche Sprachbeschreibungen („Warmer Mantel für tiefen Schnee”) anstatt durch frustrierende und limitierte Keyword-Filter.
- Rechtliches Dokument-Retrieval: Massive Verträge und EU-Regulierungsdokumente werden präzise durchsuchbar gemacht. Das KIT (Karlsruher Institut für Technologie) testet und entwickelt solche Retrieval-Systeme für akademische Umgebungen mit strengsten Normen.
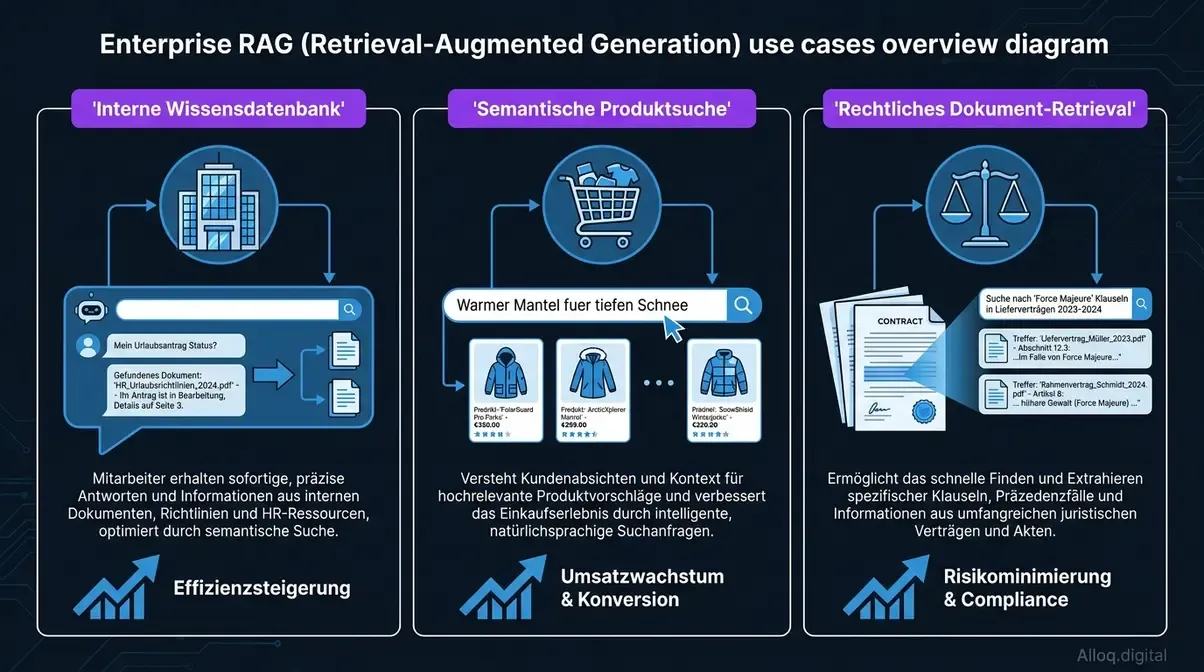 Drei typische Enterprise-Einsatzszenarien fuer Vektordatenbanken als RAG-Backend: interne HR-Wissenssysteme, semantische E-Commerce-Suche und Vertrags-Retrieval.
Drei typische Enterprise-Einsatzszenarien fuer Vektordatenbanken als RAG-Backend: interne HR-Wissenssysteme, semantische E-Commerce-Suche und Vertrags-Retrieval.
RAG-Pipeline mit Python
Eine vollständige und performante RAG-Pipeline lässt sich mit LangChain und Qdrant als In-Memory-Vektordatenbank erstaunlich kompakt programmieren:
from langchain_community.vectorstores import Qdrant
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain.chains import RetrievalQA
from langchain.text_splitter import RecursiveCharacterTextSplitter
from qdrant_client import QdrantClient
# 1. Embedding-Modell initialisieren (1536 Dimensionen für Tiefe)
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 2. Dokumente intelligent und semantisch sicher chunken
# Rekursives Splitting bewahrt Sinnabschnitte weit besser als Fixed-Size
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=512,
chunk_overlap=64,
separators=["\n\n", "\n", ".", "!", "?", " "]
)
docs = text_splitter.create_documents([unternehmens_text])
# 3. Vektordatenbank aufbauen und sofort befüllen
client = QdrantClient(":memory:")
vectorstore = Qdrant.from_documents(
documents=docs,
embedding=embeddings,
location=":memory:",
collection_name="unternehmensdaten"
)
# 4. RAG-Chain aufbauen (k=5 ähnlichste Text-Chunks retrievieren)
retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 5}
)
llm = ChatOpenAI(model="gpt-4o", temperature=0)
rag_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
return_source_documents=True # Wichtig für Compliance-Quellangaben
)
# 5. Pipeline produktiv abfragen
result = rag_chain.invoke({"query": "Wie lautet unsere Rückgabe-Richtlinie?"})
print(result["result"])Für robustere Enterprise-Systeme empfiehlt sich dringend das spätere Hinzufügen von strikten Metadaten-Filtern sowie eines Re-Ranking-Modells (beispielsweise Cohere Rerank), um die Präzision der Top-K-Ergebnisse vor der LLM-Übergabe massiv zu maximieren.
Alloq.digital in der Praxis
Vektordatenbanken sind in der Industrie extrem selten bloßer Selbstzweck - sie agieren vielmehr als hochperformante Speicherkomponente innerhalb deutlich größerer, autonomer KI-Agenten-Architekturen. Wir designen genau solche übergreifenden Systeme, die ein persistentes Gedächtnis nutzen, um über Sitzungsgrenzen hinweg aktiv zu lernen und komplexe Retrieval-Ketten verlässlich zu koordinieren.
Weitere Einblicke in die anspruchsvolle praktische Implementierung bietet unsere ausführliche Fallstudie zum KI-Sprachassistenten, in der wir eine Voice-RAG-Pipeline erfolgreich integrierten. Wenn Sie ein skalierbares KI-System für Ihre eigenen Workloads fundiert evaluieren möchten, zeigen wir Ihnen gerne die passenden KI-Agenten-Entwicklungsleistungen in einem unverbindlichen Gespräch.
Anbietervergleich: Pinecone, Qdrant, Milvus & Co.
Open-Source-Lösungen wie Qdrant und Milvus definieren den Enterprise-Markt für Vektordatenbanken neu, indem sie Cloud-unabhängige Skalierbarkeit für sensible On-Premise-Umgebungen bereitstellen. Diese Plattformen fordern etablierte Managed Services wie Pinecone durch massive Kostenvorteile heraus, insbesondere wenn Unternehmensdatenbanken die Grenze von einhundert Millionen Embeddings überschreiten. Evaluierungsteams bevorzugen zunehmend Systeme mit nativer Hybrid-Search-Unterstützung, um Sparse- und Dense-Vektoren effizient zu kombinieren.
Die Wahl der konkreten Datenbank ist am Ende nie eine rein akademische oder technische Entscheidung - sie manifestiert sich gnadenlos als harte Kosten- und Betriebsstrategie. Der Recall-Kosten-Kompromiss schlägt im Cloud-Umfeld extrem schnell durch. Wer hier naiv wählt, skaliert sich im schlimmsten Fall in die finanzielle Ruine. Ich empfehle grundsätzlich, mit lokalen Containern zu prototypen und erst bei bewiesenem Product-Market-Fit auf kostenintensive Serverless-Plattformen zu migrieren.
| Datenbank | Deployment | Open Source | Max Vektoren (Skalierung) | Hybrid Search (Native) | Primary Use Case |
|---|---|---|---|---|---|
| Pinecone | Nur Managed Cloud | Nein | Milliarden+ | Nein (nur Vektoren) | Enterprise RAG ohne Infra-Aufwand |
| Qdrant | Self-hosted & Cloud | Ja | Milliarden | Ja (Erweitert) | Skalierbare semantische Suchen |
| Milvus | Self-hosted (Zilliz Cloud) | Ja | 100 Milliarden+ | Nein (separat) | Hochperformante AI Search Engine |
| Weaviate | Self-hosted & Cloud | Ja | Milliarden+ | Ja (BM25 + Vektor) | Komplexe RAG & Hybrid-Apps |
| pgvector | PostgreSQL Extension | Ja | ~50 Millionen | Ja (via tsvector) | Postgres-Teams mit kleinen Workloads |
| FAISS | C++/Python Library | Ja | RAM-limitiert | Nein | Schnelles Prototyping & ML Research |
| Chroma | Local/Embedded & Server | Ja | ~5-10 Millionen | Nein | LLM-App Prototyping (LangChain) |
| Elasticsearch | Add-on im ELK-Stack | Nein (Proprietär) | Cluster-abhängig | Ja | Real-time Search mit Vektor-Upgrade |
| MongoDB | Atlas Vector Search | Nein (Proprietär) | Cluster-abhängig | Ja | Dokument-Datenbank mit Vector-Addon |
| Redis | Redis Modules Add-on | Nein (Proprietär) | RAM-limitiert | Ja | Extreme Low-Latency In-Memory Suchen |
Managed Services: Pinecone
Pinecone ist branchenweit der absolute De-facto-Standard für Teams, die keinerlei eigenen Infrastrukturaufwand oder DevOps-Overhead akzeptieren wollen. Das reine Serverless-Deployment, vollständig verwaltete HNSW-Indizes und eine absolut konsistente API machen es zur mit Abstand schnellsten Onboarding-Option auf dem Markt. Unabhängige Benchmarks messen hierbei Query-Latenzen von 1–2 ms bei starken 95 % Recall.
Die Kehrseite der Medaille: Pinecone wird bei massiver Skalierung schnell wirtschaftlich untragbar. Ab etwa 50 Millionen Vektoren wird ein Wechsel zu Qdrant oder Milvus nahezu zwingend. Zudem ist der Vendor Lock-in absolut real - Datenexporte für Terabytes an Vektoren sind kein triviales Wochenendprojekt.
Open-Source: Qdrant & Milvus
Qdrant (komplett in Rust geschrieben) ist derzeit das wohl leistungsstärkste Open-Source-System für hochpräzise Retrieval-Anforderungen. Die native Sparse-Vector-Unterstützung ermöglicht echte Hybrid Search ohne jegliche externe Zusatzkomponenten. Qdrant spart bei 100 Millionen Vektoren bis zu 80 Prozent Kosten - selbstgehostete Open-Source-Systeme schlagen reine Serverless-Anbieter bei Enterprise-Skalierung wirtschaftlich massiv.
Milvus (Apache-lizenziert) ist hingegen extrem auf massiv parallele, stark verteilte Architekturen ausgelegt. GPU-Beschleunigung via NVIDIA cuVS und Kafka-basierte Streaming-Ingestion machen es zur unangefochtenen Wahl für dedizierte Machine-Learning-Infrastruktur-Teams mit enorm hohem Ingestion-Throughput. Der initiale Betriebs- und Setup-Aufwand ist hierbei jedoch signifikant höher.
pgvector & Chroma
Die hybride Brücke pgvector (PostgreSQL) und das sehr leichtgewichtige Chroma komplettieren den Markt für kleine bis mittlere Teams. Chroma brilliert dabei als extrem simple Embedded-Datenbank für schnelle Python-Prototypen. Pgvector hingegen punktet gewaltig durch die nahtlose Integration in das bestehende SQL-Ökosystem und erspart Unternehmen die zeitaufwändige Beschaffung und Freigabe einer komplett neuen Technologie-Infrastruktur.
Nachteile und Limitierungen: Der ehrliche Blick
Infrastrukturkosten eskalieren in Vektorprojekten häufig unbemerkt, weil HNSW-Indizes bei wachsenden Datenmengen exponentiell mehr Arbeitsspeicher verbrauchen. Diese speicherintensive Natur zwingt Entwicklungsteams oft zu kostspieligen vertikalen Skalierungen, bevor sie echte horizontale Sharding-Strategien implementieren können. CTOs begegnen diesem architektonischen Risiko zunehmend mit Product-agnostischen Abstraktionsschichten, um den gefürchteten Vendor Lock-in bei stark proprietären Cloud-Anbietern proaktiv zu verhindern.
Trotz des massiven Hypes sind Vektordatenbanken keineswegs unfehlbare Wunderwaffen. Sie bringen eine völlig neue Kategorie von Komplexität und subtilen Fehlermodi in die Produktionsumgebung. Wer diese systemischen Schwächen nicht bereits in der frühen Designphase der RAG-Architektur knallhart einkalkuliert, baut sich eine kostenintensive Blackbox voller kaum debuggbarer Halluzinationen.
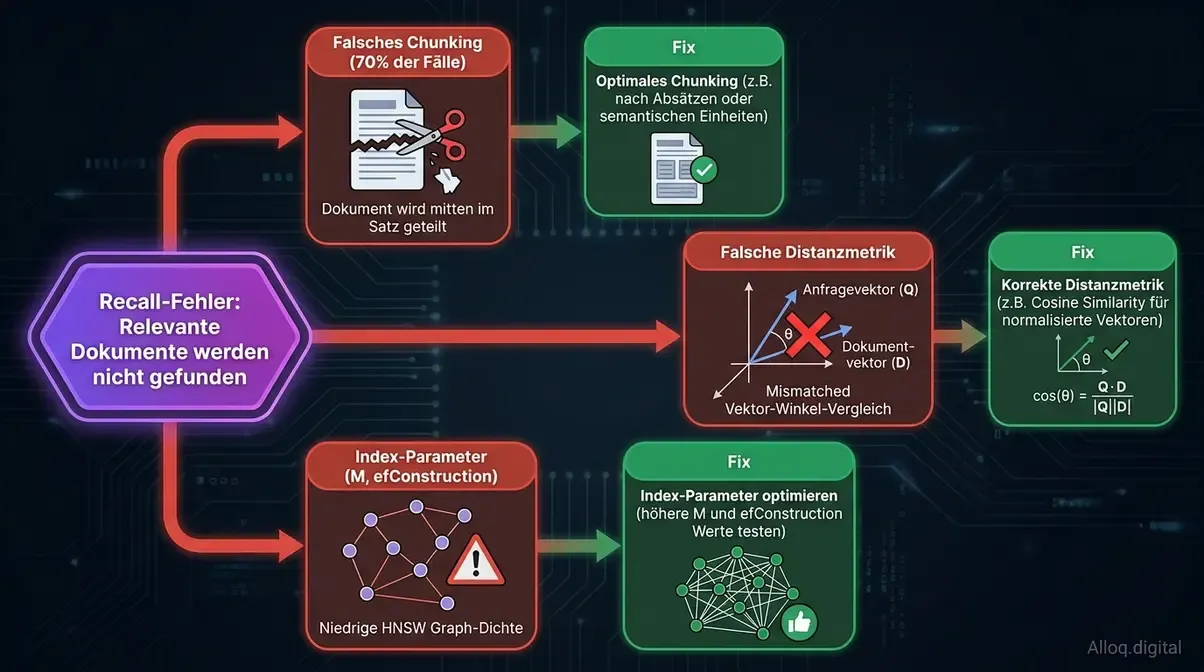 Recall-Fehler-Debugging in drei Schritten: Falsches Chunking verursacht 70% aller Ausfaelle - der Fehler liegt meist im Ingestion-Design, nicht im Index.
Recall-Fehler-Debugging in drei Schritten: Falsches Chunking verursacht 70% aller Ausfaelle - der Fehler liegt meist im Ingestion-Design, nicht im Index.
Debugging & Recall-Fehler
Im Gegensatz zu einer deterministischen SQL-Abfrage, die bei einem Fehler transparent einen leeren Table-Return liefert, gibt eine Vektorsuche immer ein Ergebnis zurück - selbst wenn der semantisch nächste Nachbar meilenweit von der eigentlichen Suchintention entfernt liegt (Out-of-Distribution Problem). Dies macht das operative Debugging von fehlerhaften KI-Antworten extrem zeitaufwändig und frustrierend.
Falsches Chunking verursacht schätzungsweise 70 Prozent aller Recall-Ausfälle - Unternehmen suchen Fehler häufig bei der Datenbank, obwohl das Ingestion-Design die tatsächliche Ursache darstellt. Wenn der semantische Sinnabschnitt in der Mitte grob zerschnitten wurde, kann der HNSW-Index die Relevanz des Textes mathematisch unmöglich korrekt bewerten.
Infrastruktur & Skalierung
HNSW-Indizes erkaufen sich ihre brillante Suchgeschwindigkeit mit einem extrem exorbitanten RAM-Bedarf. Um Latenzen niedrig zu halten, muss der gesamte Navigations-Graph vollständig im teuren Arbeitsspeicher der Server vorgehalten werden. Ein Cluster, der Milliarden von hochdimensionalen Embeddings hält, benötigt schnell hunderte Gigabyte an purem RAM.
Zusätzlich belasten massive Re-Indexierungen die CPU stark. Wenn das zugrundeliegende Embedding-Modell in der Pipeline aktualisiert oder ausgetauscht wird, müssen sämtliche Bestandsdaten in der Datenbank restlos neu berechnet und komplett neu indexiert werden - ein Prozess, der bei großen Clustern enorme Compute-Kosten verursacht und tagelang dauern kann.
Vendor Lock-in minimieren
Die rasante Marktentwicklung verführt viele Entwicklungsteams dazu, proprietäre Datenbank-Features tief und unüberlegt in die eigene Kernapplikation einzuweben. Ein späterer Wechsel des Anbieters wird dadurch wirtschaftlich komplett unmöglich gemacht. Isolationsschichten (wie das Repository-Pattern in der Softwareentwicklung) sind hier absolut Pflicht, um die KI-Infrastruktur flexibel zu halten. Weiterführende strategische Leitlinien zur sauberen KI-Einführung finden Entscheider in unserem umfangreichen KMU-Leitfaden.
FAQ
Was ist der Unterschied zwischen einer Vektordatenbank und PostgreSQL? PostgreSQL sucht basierend auf exakten Schlüsselwörtern und strukturierten Datenschemata (Zeilen und Spalten). Eine Vektordatenbank sucht hingegen nach mathematischen Repräsentationen und identifiziert inhaltliche Ähnlichkeiten in völlig unstrukturierten Daten (Text, Bild, Audio), auch wenn exakte Keywords komplett fehlen. Erst durch Erweiterungen wie pgvector erhält PostgreSQL rudimentäre Vektorsuch-Fähigkeiten.
Warum brauchen LLMs eine Vektordatenbank für RAG? Große Sprachmodelle (LLMs) haben keinerlei Zugriff auf proprietäre, firmeninterne Daten und leiden oft unter Halluzinationen. Eine Vektordatenbank fungiert als externes, durchsuchbares Gedächtnis, das dem LLM in Millisekunden die relevantesten Fakten zu einer Anfrage liefert. Dieser gesicherte Kontext ermöglicht es dem KI-System, präzise und fachlich korrekte Antworten ohne riskantes Modell-Finetuning zu generieren.
Welche Vektordatenbank ist die beste für RAG-Anwendungen? Es gibt keine universell „beste” Lösung, da die Wahl stark vom spezifischen Use Case abhängt. Pinecone glänzt durch sein wartungsfreies, extrem schnelles Setup für kleine bis mittlere Cloud-Projekte. Qdrant und Milvus dominieren hingegen im hochskalierenden Enterprise-Segment, da sie massive Kostenkontrolle bei On-Premise-Hostings und bei riesigen Datensätzen ab 100 Millionen Embeddings bieten.
Wie viele Dimensionen hat ein typisches Embedding? Die Dimensionalität hängt vollständig vom gewählten KI-Embedding-Modell ab. Gängige Standardmodelle von OpenAI (wie text-embedding-ada-002 oder V3) erzeugen Vektoren mit exakt 1.536 Dimensionen. Leistungsstarke Open-Source-Modelle rangieren meist zwischen 384 und 1.024 Dimensionen, wobei eine höhere Dimensionszahl feinere semantische Details erfassen kann, aber zwingend mehr Speicherplatz erfordert.
Was kostet der Betrieb einer Vektordatenbank? Die Betriebskosten skalieren direkt mit der Menge der Vektoren und dem erforderlichen Arbeitsspeicher. Managed Services wie Pinecone starten günstig im Serverless-Modell, können aber bei zweistelligen Millionen-Vektoren monatlich auf hunderte bis tausende Dollar anwachsen. Selbstgehostete Open-Source-Lösungen auf eigener Kubernetes-Infrastruktur erfordern zwar erhebliches DevOps-Wissen, senken die monatlichen reinen Datenbankkosten bei großen Clustern jedoch massiv.
Fazit
Der Boom rund um Generative KI hat Vektordatenbanken in absoluter Rekordzeit aus der akademischen Nische direkt in das absolute Herz moderner Enterprise-Architekturen katapultiert. Vom raschen Setup mit Pinecone bis hin zu massiv skalierbaren Kubernetes-Clustern mit Milvus existiert heute für jedes Budget und jede Sicherheitsanforderung das passende, marktreife Toolset.
Doch der entscheidende Faktor für den langfristigen Projekterfolg bleibt das technische Verständnis des Recall-Kosten-Kompromisses. Wer blindly höchste Präzision anfordert, ohne die exorbitanten Hardwarekosten für Arbeitsspeicher und CPU zu kalkulieren, wird von den laufenden Infrastrukturkosten seiner Retrieval-Systeme schnell eingeholt. Eine durchdachte, hybride Architekturplanung ist unerlässlich. Wenn Sie dabei erfahrene Unterstützung suchen, prüfen Sie gerne unsere Expertise in der professionellen KI-Integration.