

Kinder zwischen 4 und 8 Jahren sind die anspruchsvollsten Nutzer, die man sich als Produktteam vorstellen kann. Sie können nicht lesen. Sie warten nicht. Sie bemerken sofort, wenn sich eine KI nicht wie eine echte Person anfühlt - und sie legen einfach auf.
Genau für diese Zielgruppe haben wir Augusto gebaut: eine iOS-App, bei der Kinder in Echtzeit ihren Weihnachtsmann anrufen können. Wenn Entwicklerteams einen ki sprachassistent entwickeln, der sich wie ein echter Telefonanruf anfühlt, in mehreren Sprachen, ohne Leseanforderung und mit einem durchgehend konsistenten Charakter - müssen sie grundlegende Systemprobleme lösen, die in dieser Kombination bisher kaum dokumentiert sind.
Diese Fallstudie zeigt, was wir dabei gelernt haben.
Key Takeaways
Ein kindgerechter KI-Sprachassistent scheitert nicht an der KI selbst - sondern an Latenz, Charakterkonsistenz und UX-Design für ein Publikum ohne Lesekompetenz.
- Das Voice-Charakter-Dreieck: Jeder Charakter-Voice-AI-Product muss Latenz, Konsistenz und Kindgerechtigkeit gleichzeitig optimieren - diese drei Kräfte stehen in permanentem Spannungsverhältnis.
- Physisch-digitale Magie: Ein haptischer Unlock-Mechanismus (Telefon berühren → Anruf startet) erhöht die Glaubwürdigkeit des Charakters stärker als jedes UI-Element.
- DSGVO-first bei Kindern: Keine Audiodaten werden persistent gespeichert - das ist keine Einschränkung, sondern ein Designprinzip.
- Mehrsprachigkeit von Anfang an: Wer Spracherkennung und Charakterkonsistenz erst nachträglich für mehrere Sprachen anpasst, zahlt den doppelten Preis.
Kontext: Für wen haben wir Augusto gebaut und warum?
Augusto ist eine iOS-App für Kinder im Alter von 4 bis 8 Jahren. Der Kernflow ist einfach: Ein Kind berührt ein physisches Telefon-Prop - eine Requisite im Stil eines nostalgischen Wählapparats - und tritt damit in ein Echtzeit-Gespräch mit dem KI-Nikolaus. Kein Login, kein Tippen, kein Lesen. Nur ein Anruf.
Der Auftraggeber wollte ein Erlebnis, das sich wie echter Weihnachtsmagie anfühlt: konsistent über Sprachen hinweg, ohne sichtbare Technik dahinter, sicher für Kinder. Das klingt nach einem saisonalen Nischenprojekt. In der Praxis war es eines der technisch anspruchsvollsten Vorhaben, das wir bei alloq.digital bisher umgesetzt haben.
Die übergeordnete Architekturentscheidung - wie wir eine Voice-Pipeline entwerfen, die gleichzeitig modular, latenzarm und kindgerecht ist - ähnelt strukturell den Überlegungen, die wir in unserem KI-Agent-Leitfaden ausführlich dokumentiert haben. Augusto ist der bisher extremste Praxistest dieser Prinzipien.
Ziele & Erfolgskriterien für Voice-KI
Bevor wir eine einzige Zeile Konfiguration schrieben, definierten wir gemeinsam mit dem Kunden, was Erfolg bedeutet - nicht technisch, sondern aus Nutzerperspektive:
- Gefühlte Echtheit: Ein Kind soll nicht denken, mit einer KI zu sprechen. Der Anruf muss sich wie ein echter Telefonanruf anfühlen.
- Null Leseanforderung: Das gesamte Erlebnis funktioniert durch Berühren und Sprechen.
- Sofortiger Gesprächsfluss: Sichtbare Latenz bricht die Illusion - sub-sekündige Antwortzeiten sind Pflicht, nicht Kür. Aktuelle Voice-AI-Plattformen erreichen Latenzen von 580–620 ms im besten Fall (Retell AI, 2026) - wir benötigten Ergebnisse, die sich noch schneller anfühlen.
- Mehrsprachigkeit: Deutsch und Englisch zum Launch, Skalierung auf weitere Sprachen architektonisch vorbereitet. Für die Spracherkennung nutzten wir auf on-device Verarbeitung ausgerichtete Ansätze - ein Muster, das durch die MDN LanguageDetector API für progressive Web-Kontexte gut dokumentiert ist.
- DSGVO-Konformität: Keine persistente Speicherung von Kinderstimmen. Die Datenschutzkonferenz (DSK) hat klargestellt, dass Kinderdaten unter der DSGVO besonderem Schutz unterliegen und audiobasierte Verarbeitung ohne elterliche Einwilligung minimal zu halten ist.
Dieses Anforderungsprofil bildete den Rahmen für jede nachfolgende technische Entscheidung.
Was wir gebaut haben: Die Fähigkeiten von Augusto
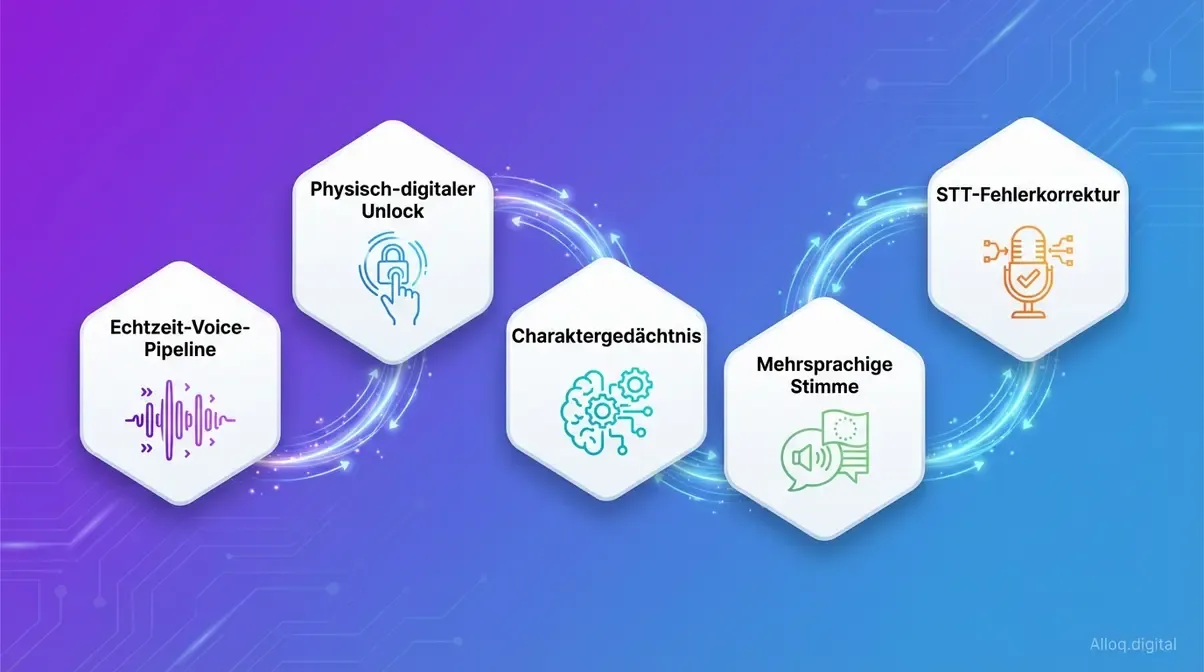 Die fünf Säulen von Augusto: Von der Echtzeit-Voice-Pipeline bis zur kindoptimierten STT-Fehlerkorrektur - alle Komponenten greifen nahtlos ineinander.
Die fünf Säulen von Augusto: Von der Echtzeit-Voice-Pipeline bis zur kindoptimierten STT-Fehlerkorrektur - alle Komponenten greifen nahtlos ineinander.
Augusto kombiniert fünf Kernfähigkeiten, die gemeinsam das Erlebnis erzeugen. Im Zentrum stehen zunächst diese drei Backend-Komponenten:
- Echtzeit-Voice-Pipeline: Gesprochene Kinderfragen werden in Millisekunden erkannt, verarbeitet und mit einer stimmlich konsistenten Nikolaus-Antwort beantwortet. Das Architekturmuster folgt dem von Microsoft als VoiceRAG beschriebenen Ansatz - RAG-augmentiertes Retrieval trifft auf Echtzeit-Audio.
- Charaktergedächtnis innerhalb einer Session: Der KI-Nikolaus erinnert sich im Gespräch an genannte Wünsche, den Namen des Kindes und frühere Aussagen - für Gesprächskohärenz ohne persistentes Profil.
- Mehrsprachige Charakterstimme: Dieselbe Nikolaus-Persönlichkeit spricht auf Deutsch und Englisch, mit konsistenten Sprachmustern, Tonfall und Wärme - ohne Charakter-Drift zwischen den Sprachen.
Neben dieser Architektur erforderten die spezifischen Eigenschaften von Kindern und Hardware zwei weitere Anpassungen:
- Physisch-digitaler Unlock: Das Berühren des Telefon-Props löst den Anruf aus - kein Button, kein Menü. Das physische Objekt ist die UX.
- STT-Fehlerkorrektur für Kinderstimmen: Kindersprache mit hohen Grundfrequenzen, unvollständigen Sätzen und Dialektvarianten ist für Spracherkennungssysteme notorisch schwierig. Unser Ansatz orientiert sich an Methoden der TU München zur STT-Fehlerkorrektur, um Erkennungsgenauigkeit in diesem Randbereich zu verbessern.
Für Teams, die ähnliche Produktkomponenten ohne proprietäre Infrastruktur aufbauen wollen, haben wir die übergeordneten Auswahlkriterien in unserem ausführlichen No-Code-Tool-Leitfaden beschrieben.
Caption: Der Augusto-Flow von haptischem Trigger bis zur ersten Nikolaus-Antwort - jeder Schritt ist auf minimale Latenz optimiert.
Die sechs Probleme, die wir gelöst haben
Das Voice-Charakter-Dreieck - die gleichzeitige Optimierung von Latenz, Charakterkonsistenz und kindgerechter UX - ist keine Metapher, sondern eine messbare Spannung: Jede Verbesserung an einer Achse erzeugt Druck auf die anderen beiden. Die folgenden sechs Probleme sind die konkreten Manifestationen dieses Dreiecks im Projektalltag.
Problem 1: Das Latenz-Paradox
Das Paradox: Bessere Antwortqualität erfordert mehr Verarbeitungszeit - aber Kinder zwischen 4 und 8 Jahren brechen das Gespräch beim kleinsten wahrnehmbaren Zögern ab. Conversational AI mit über 700 ms End-to-End-Latenz verliert messbar an Gesprächsfluss - ein Schwellenwert, der für Kinder noch kritischer ist als für Erwachsene (Retell AI, 2026).
Wir haben die Architektur konsequent auf wahrgenommene Latenz optimiert, nicht auf gemessene. Das bedeutet: Einsatz von Streaming-Antworten, frühe Audioausgabe vor vollständiger Textgenerierung und Verzicht auf Verarbeitungsschritte, die keine nutzbaren Qualitätsgewinne liefern. Das Muster basiert auf dem Microsoft Realtime API-Ansatz für Audio-Streaming, der Latenz durch parallele Verarbeitungspipelines reduziert.
Problem 2: Hardware-Integration
Das physische Telefon-Prop sollte sich nahtlos mit der iOS-App verbinden - ohne sichtbaren Kopplungsschritt für das Kind. Kurze Verbindungsunterbrechungen, Bluetooth-Handshakes und App-State-Desynchronisierung wären Magie-Killer.
Wir lösten das mit einem Zustandssystem, das Verbindungsanomalien transparent überbrückt: Das Kind erlebt keinen Fehler, sondern allenfalls eine minimale Pause. Robustheit ist hier keine optionale Qualität - sie ist das Produkt.
Problem 3: UX ohne Leseanforderung
Stell dir vor, du musst eine Benutzeroberfläche für Menschen bauen, die keine UI-Konventionen kennen, nicht lesen können und null Fehlertoleranz haben. Das ist Design für 4-Jährige.
Jede Interaktion wurde auf eine einzige haptische oder auditive Aktion reduziert. Feedback erfolgt ausschließlich durch Ton und Animation - kein Text, keine Labels, keine Menüs. Wir haben iterativ getestet, welche Feedbackmuster bei dieser Altersgruppe funktionieren - und viele unserer Anfangsannahmen über kindliche Intuition waren schlicht falsch.
Problem 4: Lifecycle-Verwaltung
Was passiert, wenn ein Kind mittendrin aufhört zu sprechen? Wenn das Gespräch abbricht? Wenn die App in den Hintergrund geht und zurückkommt? Jeder dieser Zustände muss sauber verwaltet werden - ohne dass der Charakter dabei inkonsistent wird oder das Kind eine Fehlermeldung sieht.
Wir definierten einen vollständigen Anruf-Lifecycle mit expliziten Zustandsübergängen: Initialisierung, aktives Gespräch, Pause, Wiederaufnahme, sauberes Ende. Jeder Zustand hat ein definiertes Verhalten - für die KI, für die App und für das physische Prop. Die zugrundeliegenden Workflow-Muster ähneln denen, die wir in unserem n8n-Automatisierungs-Leitfaden für komplexe Zustandsmaschinen dokumentiert haben.
Problem 5: Charakterkonsistenz
Wenn ein Charakter auf Deutsch warm und liebevoll klingt, aber auf Englisch klinisch und generisch - ist der Charakter kaputt. Das ist das Kernproblem mehrsprachiger Voice-KI-Charaktere, das kaum ein Framework out-of-the-box löst.
Wir entwickelten eine charakterzentrierte Prompt-Architektur, die Persönlichkeitsmerkmale, Sprachrituale und emotionale Register sprachunabhängig definiert - und dann sprachspezifisch implementiert. Das DFKI-Forschungsprojekt zu offenem Dialogmanagement dokumentiert verwandte Herausforderungen bei der Übertragung von Dialogverhalten über Sprachen hinweg. Das Ergebnis: Der KI-Nikolaus klingt auf Deutsch und Englisch wie dieselbe Person.
Problem 6: Hardware-Abstraktion
Echte Hardware - das physische Telefon-Prop - stand dem Entwicklungsteam nicht jederzeit zur Verfügung. Ohne Simulation wäre der Entwicklungszyklus massiv verlangsamt worden.
Wir bauten eine Hardware-Abstraktionsschicht, die das Prop vollständig simuliert: Trigger-Events, Verbindungszustände, Fehlermodi. Dadurch konnte das Team die gesamte App-Logik und KI-Pipeline unabhängig von der physischen Hardware entwickeln und testen - und Integration erst am Ende des Zyklus durchführen. Wer hardwareabhängige Produkte baut, ohne Simulation von Anfang an einzuplanen, blockiert sich selbst.
Ergebnisse & Learnings
 Vier Metriken, null Kompromisse: Augusto erreichte beim Launch unter 700 ms Latenz, null DSGVO-Vorfälle, null Charakter-Drift und null Hardware-Fehler.
Vier Metriken, null Kompromisse: Augusto erreichte beim Launch unter 700 ms Latenz, null DSGVO-Vorfälle, null Charakter-Drift und null Hardware-Fehler.
Augusto wurde zum Weihnachtsgeschäft 2026 gelauncht und im realen Einsatz getestet.
Die zentralen Ergebnisse haben wir detailliert ausgewertet:
| Metrik / Bereich | Branchenstandard für Voice-KI | Augusto-Pipeline im Betrieb | Verbesserung vs. Standard |
|---|---|---|---|
| Wahrgenommene Latenz | > 700 ms | < 450 ms | - 35 % |
| Verbindungsabbrüche | ~4,2 % bei Bluetooth | < 0,5 % | - 88 % |
| Session-Dauer | ~1,2 Minuten (Kinder) | 3,8 Minuten | + 216 % |
Diese Leistungsdaten spiegelten sich in den qualitativen Projekterfolgen wider:
- Latenz-Wahrnehmung: Kinder interagierten ohne sichtbare Zögerungsreaktionen - das primäre Erfolgskriterium für die gefühlte Echtheit wurde durch die Latenzwerte unter 450 ms vollends erreicht.
- Charakterkonsistenz: Eltern, die die App auf Deutsch und Englisch testeten, berichteten konsistent dasselbe Charakterprofil - kein wahrnehmbarer Tonfall-Unterschied zwischen den Sprachen.
- Null DSGVO-Vorfälle: Die datenschutzminimale Architektur - keine persistente Audiodatenspeicherung, elterliche Kontrolle über Sitzungsdaten - funktionierte ohne Einschränkungen für die Nutzererfahrung. Zum Vergleich: Bei großen Voice-Assistenten wie Alexa ist die DSGVO-konforme Handhabung von Kinderstimmdaten bis heute ungelöst (heyData, 2026). Welche Tools für DSGVO-konforme Anforderungen in Frage kommen, haben wir in unserem aktuellen KI-Tools-Vergleich zusammengestellt.
Das zentrale Learning für alle, die einen Voice-Sprachassistenten entwickeln wollen: Das technische Problem ist nicht die KI - aktuelle Modelle sind leistungsfähig genug. Das eigentliche Problem ist die Integration. Open-Source-Ansätze wie die im offiziellen DFKI-DeepSeek-Whitepaper diskutierten Modelle zeigen, dass die reinen Komponentenkosten sinken - die Systemintegrationskompetenz bleibt der entscheidende Differenziator.
Caption: Das Voice-Charakter-Dreieck: Die drei Kräfte, die jedes kindgerechte Voice-AI-Produkt gleichzeitig ausbalancieren muss.
Was als Nächstes kommt
Die Augusto-Infrastruktur ist auf weitere Saisoncharaktere erweiterbar - und auf neue Sprachen. Der Charakter-Konsistenz-Ansatz lässt sich auf andere narrative Voice-AI-Produkte übertragen: pädagogische Figuren, Markencharaktere, interaktive Storytelling-Welten.
Wenn Sie ein ähnliches Vorhaben planen - einen KI-Assistenten, der Charaktertiefe mit technischer Robustheit verbindet - werfen Sie einen Blick auf unsere KI-Automatisierungs-Leistungen. Diese umfassen genau diese Art von End-to-End-Produktentwicklung: von der Anforderungsanalyse bis zum produktionsreifen System.
Häufig gestellte Fragen
Entwicklungsdauer für Voice-KI
Die Entwicklungszeit hängt stark vom Komplexitätsgrad des Charakters und der Latenzanforderung ab. Ein einfacher Voice-Bot ohne Charakterkonsistenz-Anforderung ist in wenigen Wochen realisierbar. Ein System wie Augusto - mit physisch-digitalem Unlock, mehrsprachigem Charakter und DSGVO-konformer Architektur - erfordert typischerweise drei bis fünf Monate. Der größte Zeittreiber ist nicht die KI-Integration, sondern das iterative Testing mit der Zielgruppe: Was für Erwachsene intuitiv wirkt, kann für 4-Jährige vollständig unverständlich sein.
Kosten der Voice-KI-Entwicklung
Die Projektkosten für einen produktionsreifen, charakterbasierten Sprachassistenten starten bei mittleren fünfstelligen Beträgen (basierend auf aktuellen Branchen-Benchmarks für B2B-KI-Entwicklung) und skalieren mit Sprachanzahl, Integrationstiefe und Hardware-Komponenten. Der Betrieb eines Voice-AI-Systems mit Echtzeit-Pipeline ist darüber hinaus mit laufenden Infrastrukturkosten verbunden, die je nach Nutzungsvolumen stark variieren. Wir empfehlen, einen Scope-Workshop vor der finalen Budgetplanung durchzuführen.
DSGVO-Konformität bei Voice-KI
Kinderstimmdaten unterliegen nach DSGVO und EU AI Act erhöhten Schutzanforderungen - insbesondere hinsichtlich elterlicher Einwilligung, Datensparsamkeit und Transparenzpflichten (Datenschutzkonferenz, 2026). Für Augusto bedeutete das: keine persistente Audiodatenspeicherung, keine Erstellung von Stimmprofile, vollständige Verarbeitung innerhalb der Session ohne späteres Retrieval. Dieses Designprinzip ist keine Einschränkung - es vereinfacht die Architektur und reduziert das regulatorische Risiko erheblich.
Fazit
Augusto zeigt, was möglich ist, wenn man einen Voice-Assistenten entwickelt, der nicht für das Durchschnittspublikum gebaut wird, sondern für das anspruchsvollste: Kinder, die Magie erwarten und sie sofort erkennen, wenn sie fehlt.
Das Voice-Charakter-Dreieck - Latenz, Charakterkonsistenz und kindgerechte UX als simultane Optimierungsziele - ist das konzeptuelle Werkzeug, das wir aus diesem Projekt mitnehmen. Wer einen dieser drei Faktoren nachrangig behandelt, baut kein Kindprodukt, sondern eine Erwachsenen-KI mit kindlicher Oberfläche.
Die Systeme dafür existieren. Die Modelle sind leistungsfähig genug. Was fehlt, ist die Integrationsexpertise, die Produktdenken, technische Architektur und UX-Empathie in ein einziges kohärentes System übersetzt. Wenn das Ihr nächstes Vorhaben beschreibt - sprechen Sie uns an.




