Make vs n8n: Kosten, KI & DSGVO im Vergleich 2025
Du stehst vor einer Entscheidung, die deine Workflows für die nächsten Jahre prägt: Make oder n8n. Die eine Plattform verspricht dir sofortige Ergebnisse ohne Servermanagement. Die andere gibt dir volle Kontrolle über Code, Daten und Kosten. Beide Optionen haben ihre Berechtigung, doch die falsche Wahl kann dich monatlich Hunderte Euro kosten oder dein KI-Projekt zum Scheitern bringen.
Das Problem ist nicht der Mangel an Informationen. Vergleichsartikel gibt es viele. Was fehlt, ist ein strategischer Blick auf die tatsächlichen Konsequenzen deiner Entscheidung. Was passiert mit deiner Rechnung, wenn dein Workflow von 100 auf 100.000 Durchläufe skaliert? Was bedeutet es konkret für die DSGVO, wenn deine Kundendaten über US-Server laufen? Und warum scheitern laut Branchenanalysen fast ein Drittel aller KI-Projekte, bevor sie Ergebnisse liefern?
Dieser Leitfaden geht über den üblichen Feature-Vergleich hinaus. Du erfährst, wie die 30%-Regel bei der Automatisierung Kosten senkt, warum API-Architektur für Entwickler entscheidend ist und welche Hardware du für Self-Hosting mit lokalen KI-Modellen brauchst. Fakten statt Versprechen, damit du eine fundierte Entscheidung triffst.
Key Takeaway
Bei der Entscheidung make vs n8n hängt alles von deinem technischen Know-how und Skalierungsbedarf ab. Beide Plattformen automatisieren Workflows, unterscheiden sich aber grundlegend in Architektur und Kostenstruktur.
- Make ist ideal für schnelle, visuelle Automatisierungen ohne Server-Management (SaaS)
- n8n bietet als Fair-Code-Lösung volle Datenkontrolle durch Self-Hosting und massive Kostenvorteile bei hohen Volumina
- Für komplexe KI-Agenten und LangChain-Integrationen ist n8n die flexiblere Wahl
- Die Kostenunterschiede werden erst bei Skalierung deutlich sichtbar
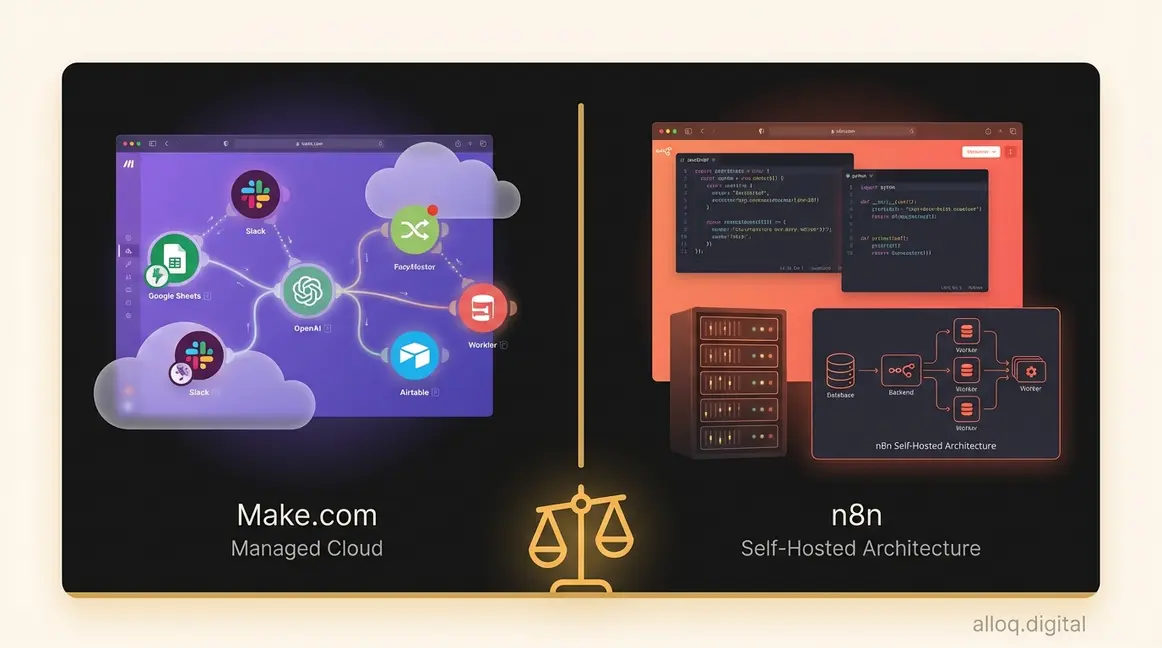
Vergleich von Workflow-Automatisierungsplattformen (Make vs. n8n)
 Die vier strategischen Entscheidungsfaktoren im Überblick: Abrechnungsmodell, Hosting-Optionen, KI-Bereitschaft und Lernkurve im direkten Vergleich.
Die vier strategischen Entscheidungsfaktoren im Überblick: Abrechnungsmodell, Hosting-Optionen, KI-Bereitschaft und Lernkurve im direkten Vergleich.
Die Debatte make vs n8n lässt sich nicht mit einem einfachen „Tool A ist besser” beantworten. Beide Plattformen lösen ähnliche Probleme, verfolgen aber grundlegend verschiedene Philosophien. Make setzt auf fully managed environments mit maximaler Benutzerfreundlichkeit. n8n gibt dir als Fair-Code-Plattform die technische Kontrolle zurück, verlangt dafür aber mehr Eigenverantwortung.
Für dich als kostenbewussten Nutzer bedeutet das: Deine Entscheidung hängt weniger von einzelnen Features ab als von drei strategischen Faktoren. Erstens, wie sich die Kosten bei Skalierung entwickeln. Zweitens, wo deine Daten liegen und wer darauf Zugriff hat. Drittens, wie bereit dein Tech-Stack für komplexe KI-Agenten ist.
Kernunterschiede: Operations vs. Executions (Kostenfalle vermeiden)
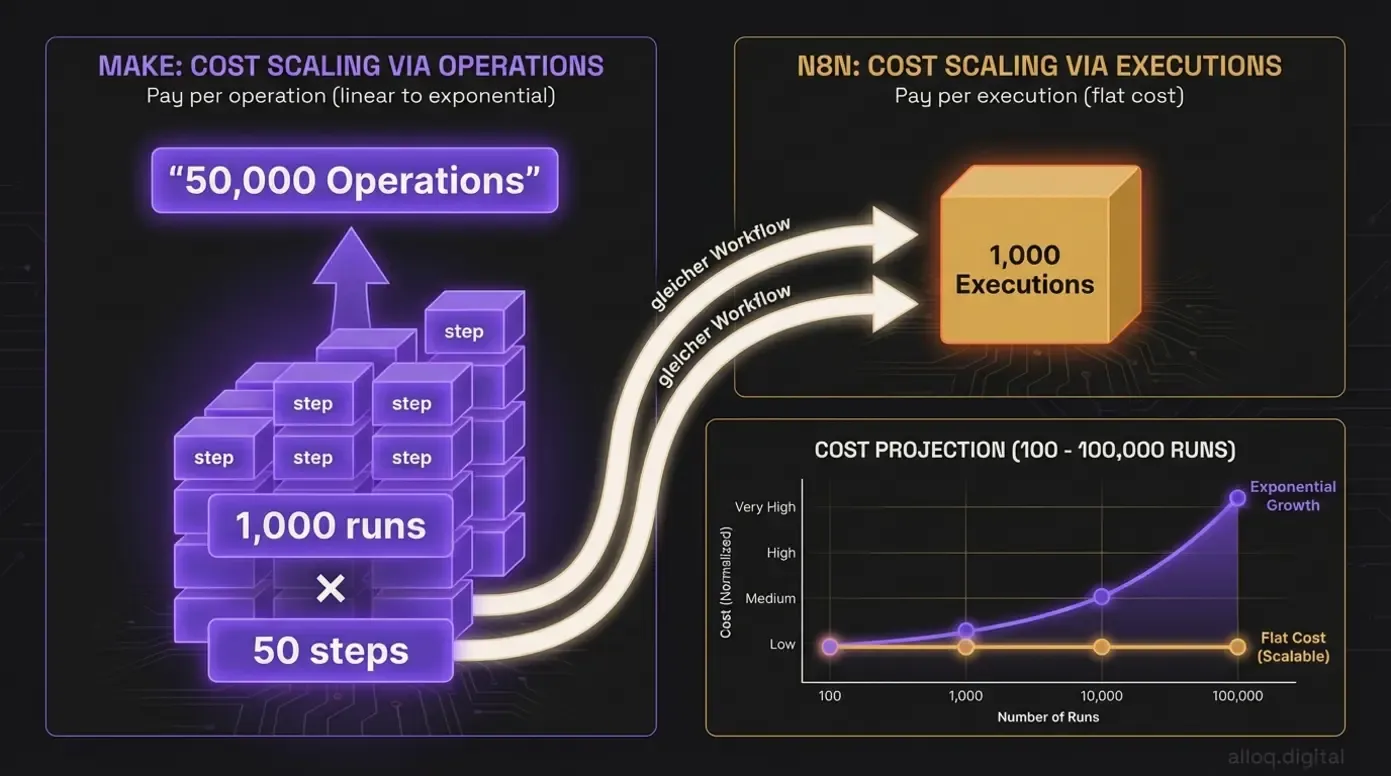 Die Kostenfalle im Detail: Derselbe Workflow mit 50 Schritten kostet bei Make 50.000 Operations, bei n8n nur 1.000 Executions — der Unterschied wächst exponentiell bei Skalierung.
Die Kostenfalle im Detail: Derselbe Workflow mit 50 Schritten kostet bei Make 50.000 Operations, bei n8n nur 1.000 Executions — der Unterschied wächst exponentiell bei Skalierung.
Der zentrale Preisunterschied zwischen Make und n8n liegt in der Abrechnungslogik. Make berechnet jede einzelne Operation, also jeden Schritt innerhalb eines Workflows. n8n rechnet dagegen pro Execution, also pro komplettem Workflow-Durchlauf, unabhängig von der Anzahl der Schritte.
In der Praxis bedeutet das: Ein Workflow mit 50 Schritten, der 1.000 Mal pro Monat läuft, verbraucht bei Make 50.000 Operations. Bei n8n sind es 1.000 Executions. Dieser Unterschied wird bei Skalierung zum entscheidenden Kostenfaktor.
| Faktor | Make (Pro Plan) | n8n (Self-Hosted) |
|---|---|---|
| Abrechnungseinheit | Pro Operation | Pro Execution |
| 100.000 Aktionen/Monat | ca. 29–99 € (je nach Plan) | ca. 0 € (nur Serverkosten) |
| Skalierung auf 500.000 | Planupgrade nötig (ab 99 €+) | Gleiche Serverkosten |
| Versteckte Kosten | Overage-Gebühren | Server-Wartung, DevOps-Zeit |
Laut einer Studie von Simon-Kucher (2024) wirkt KI ab 30 Prozent Automatisierung signifikant auf Geschäftsprozesse. Das bedeutet: Wer diesen Schwellenwert erreichen will, muss die Skalierungskosten von Anfang an einkalkulieren. Bei Make können die Kosten dann schnell steigen, während n8n im Self-Hosting nahezu linear bleibt.
Für eine visuelle Erklärung der Kostenunterschiede und Backend-Nutzung, schau dir dieses Video an:
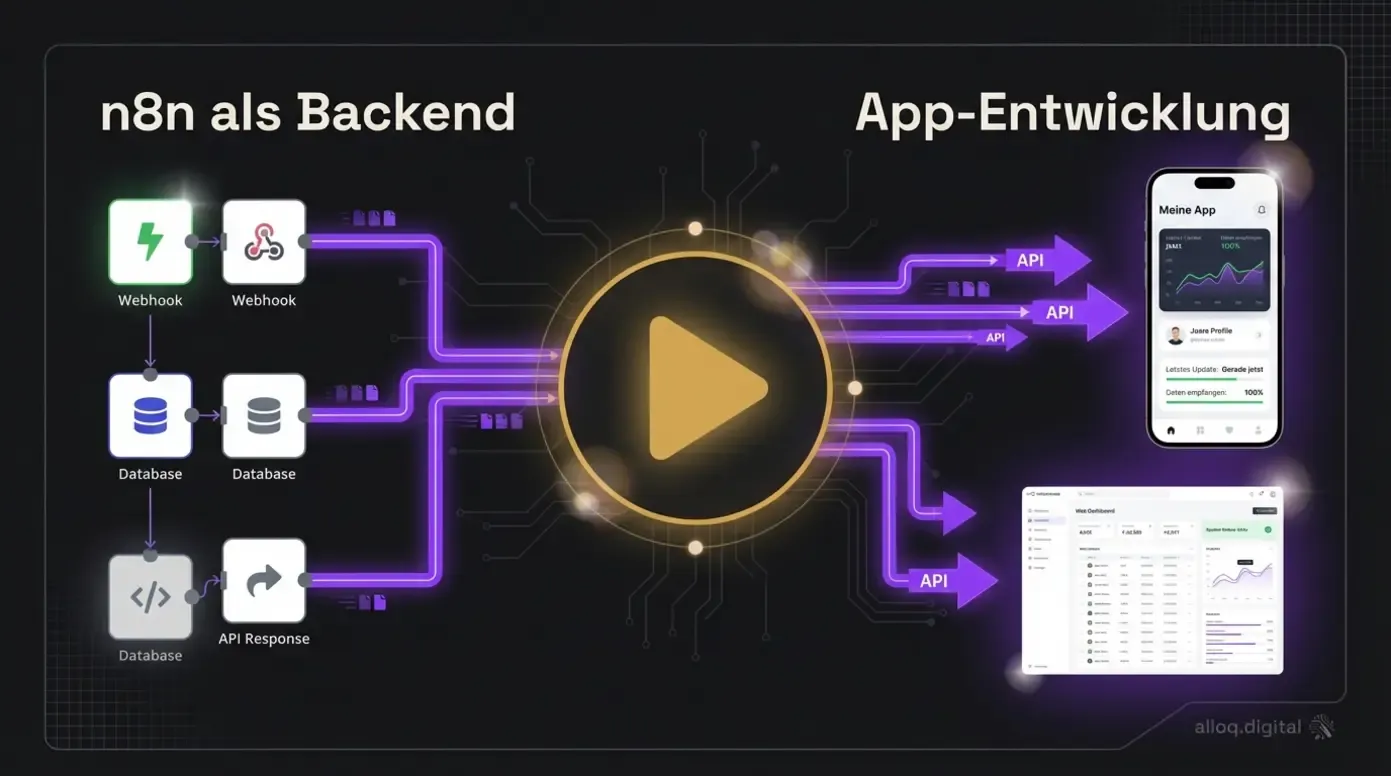 Video-Erklärung: So nutzt du n8n als vollwertiges Backend für App-Entwicklung — von Webhooks über Datenbankanbindung bis zur API-Auslieferung.
Video-Erklärung: So nutzt du n8n als vollwertiges Backend für App-Entwicklung — von Webhooks über Datenbankanbindung bis zur API-Auslieferung.
Wenn du Unterstützung bei der professionellen Umsetzung von Automatisierungs-Workflows brauchst, kann eine strategische Planung dir helfen, die Kostenfalle von Anfang an zu umgehen.
Hosting & Datenschutz: Cloud vs. Self-Hosting (DSGVO)
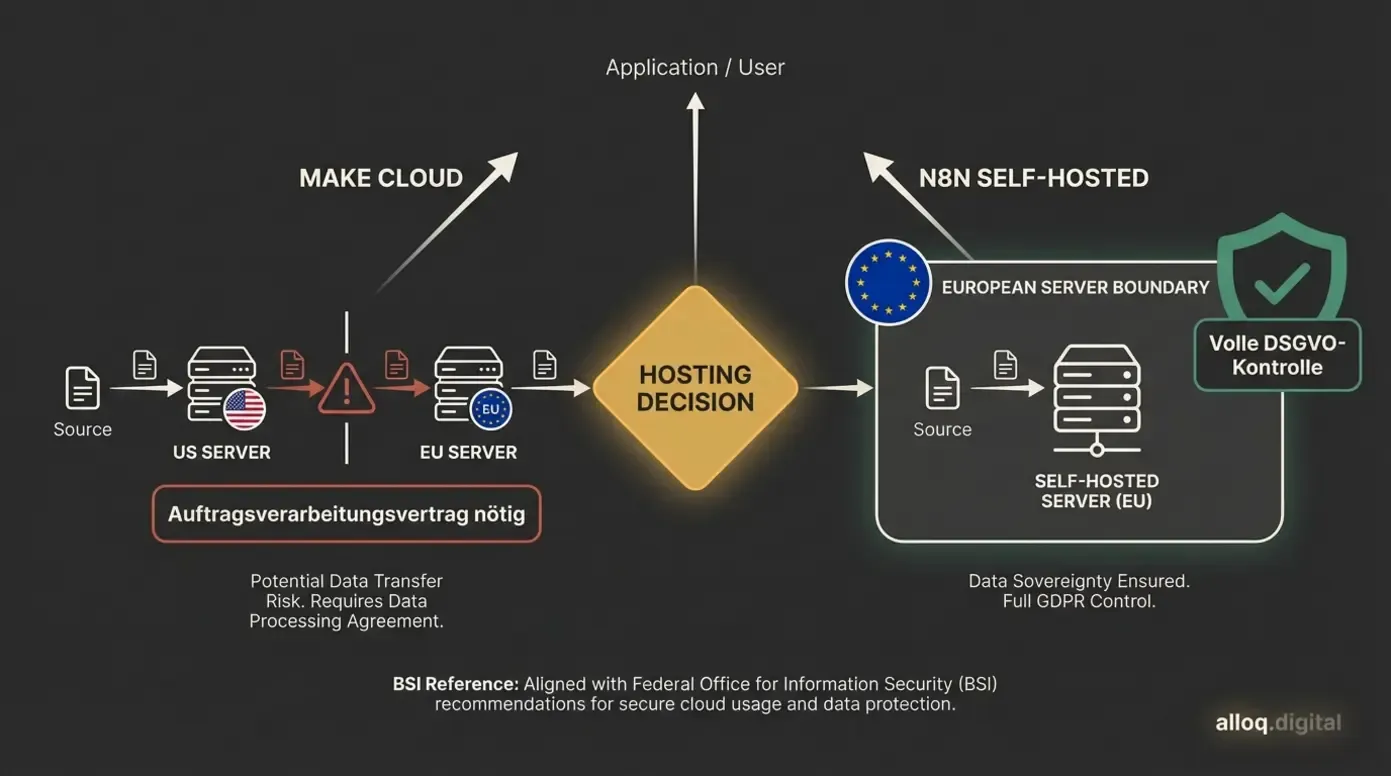 Datensouveränität im Vergleich: Bei Make laufen Daten über externe Cloud-Server, bei n8n Self-Hosting behältst du die volle DSGVO-konforme Kontrolle über den Datenstandort.
Datensouveränität im Vergleich: Bei Make laufen Daten über externe Cloud-Server, bei n8n Self-Hosting behältst du die volle DSGVO-konforme Kontrolle über den Datenstandort.
Die Frage nach dem Hosting ist nicht nur technisch, sondern auch rechtlich relevant. Make läuft als vollständig verwaltete Cloud-Lösung auf Servern in den USA und der EU. Du musst dich um nichts kümmern, gibst aber die Kontrolle über deine Daten ab. n8n ermöglicht dagegen Self-Hosting auf eigenen Servern oder bei einem europäischen Provider deiner Wahl.
Für europäische Unternehmen mit hoher risk sensitivity ist dieser Unterschied oft entscheidend. Wenn du Kundendaten, Gesundheitsdaten oder Finanzdaten verarbeitest, kann Self-Hosting die DSGVO-Konformität erheblich vereinfachen. Du weißt genau, wo deine Daten liegen, und musst keine Auftragsverarbeitungsverträge mit US-Anbietern prüfen.
Dabei gilt: Self-Hosting bedeutet auch Verantwortung. Das Bundesamt für Sicherheit in der Informationstechnik (BSI) weist darauf hin, dass beim Self-Hosting die Verantwortung für Sicherheitsupdates und Konfiguration vollständig beim Betreiber liegt. Der Fair-Code-Ansatz von n8n gibt dir die Freiheit, den Quellcode zu prüfen und anzupassen, aber du musst diese Freiheit auch aktiv nutzen.
AI Readiness: Warum 85% der Projekte scheitern (und wie n8n hilft)
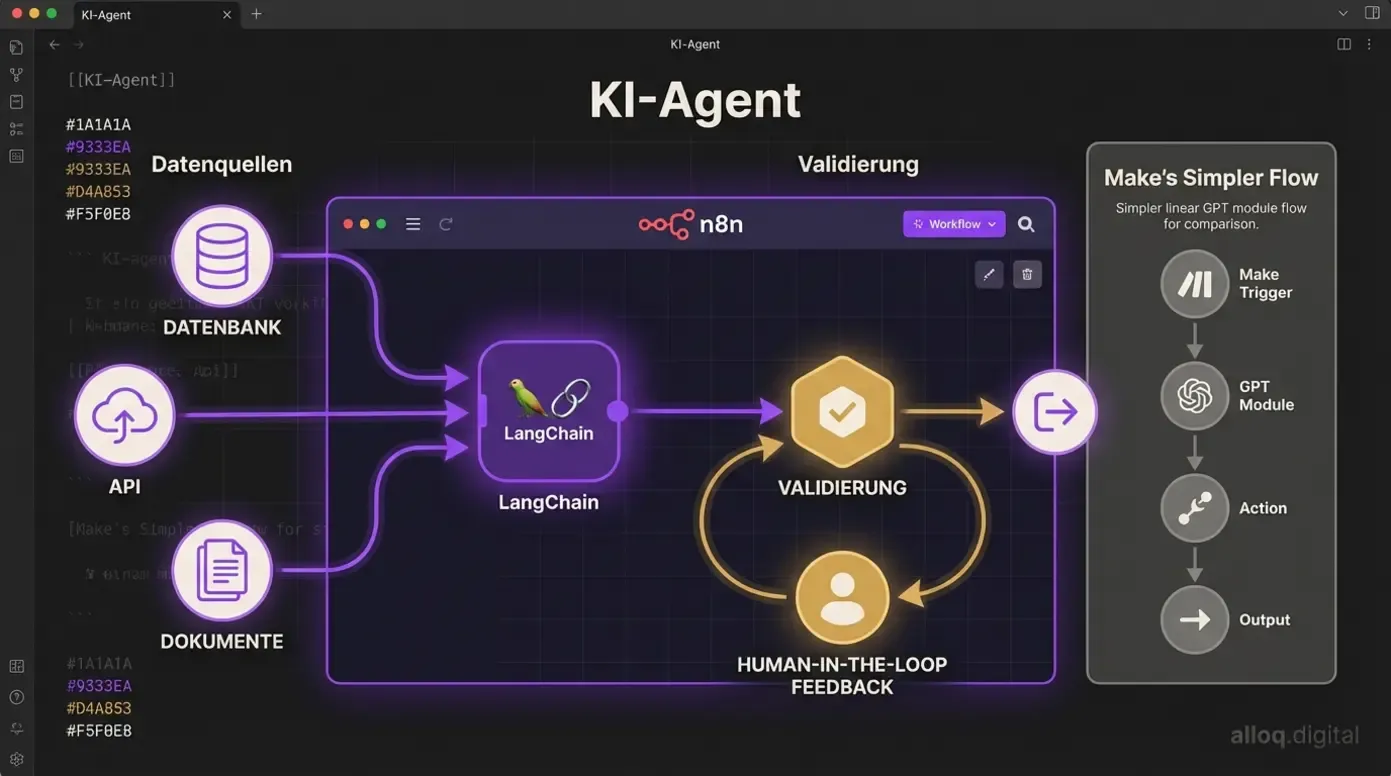 KI-Agent-Workflows im Vergleich: n8n ermöglicht mit nativer LangChain-Integration komplexe Agenten mit Validierung und Human-in-the-Loop — Make beschränkt sich auf lineare KI-Module.
KI-Agent-Workflows im Vergleich: n8n ermöglicht mit nativer LangChain-Integration komplexe Agenten mit Validierung und Human-in-the-Loop — Make beschränkt sich auf lineare KI-Module.
Laut einer Gartner-Analyse (2025) scheitern bis zu 30% aller KI-Projekte in Unternehmen. Die Gründe sind oft weniger technisch als organisatorisch: fehlende Datenqualität, keine klare Strategie und Tools, die nicht flexibel genug sind, um komplexe AI Agents abzubilden.
Hier zeigt sich ein deutlicher Unterschied. Make bietet solide KI-Integrationen für standardisierte Aufgaben wie Textgenerierung oder Bildanalyse. Für einfache Automationen, etwa ein GPT-Modul, das E-Mails zusammenfasst, reicht das völlig aus. Doch bei komplexen Agenten-Architekturen, bei denen ein KI-Modell Entscheidungen trifft, Tools aufruft und menschliches Feedback einbezieht (Human-in-the-loop), stößt Make an Grenzen.
n8n integriert LangChain direkt als nativen Baustein. Das ermöglicht Workflows, in denen ein KI-Agent eigenständig zwischen verschiedenen Datenquellen wechselt, Zwischenergebnisse prüft und bei Unsicherheiten einen Menschen einbezieht. Diese Architektur kann dazu beitragen, die typischen Fehlerquellen von KI-Projekte zu reduzieren, weil sie Halluzinationen durch strukturierte Validierungsschritte abfängt.
Die 30%-Regel zeigt: Automatisierung entfaltet erst ab einem signifikanten Automatisierungsgrad ihre volle Wirkung. Wer dieses Ziel mit KI-Agenten erreichen will, braucht ein Tool, das mit der Komplexität mitwächst.
API-Architektur & Protokoll-Standards (Deep Dive für Entwickler)
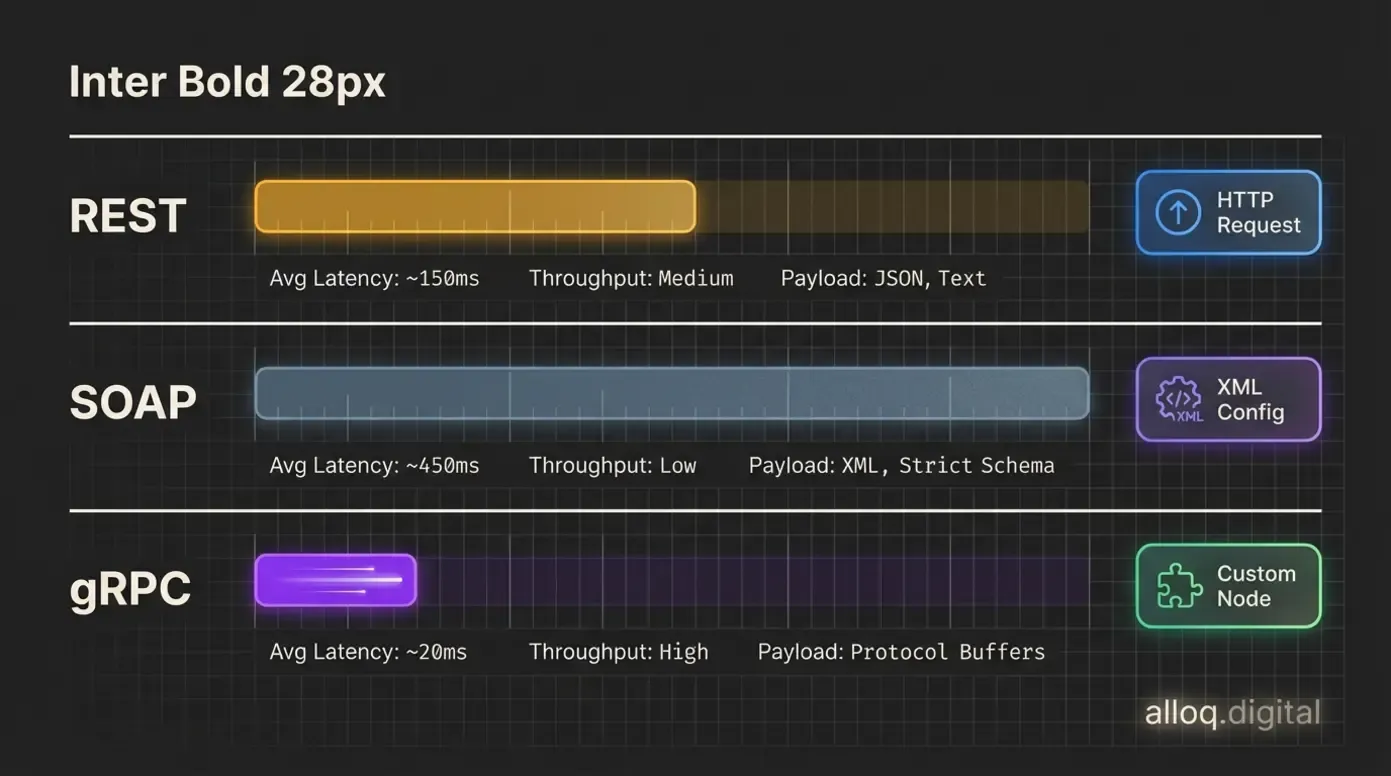 Drei Protokolle, drei Anwendungsfälle: REST für Standard-APIs, SOAP für Enterprise-Legacy-Systeme und gRPC für performante Microservice-Kommunikation — alle in n8n nutzbar.
Drei Protokolle, drei Anwendungsfälle: REST für Standard-APIs, SOAP für Enterprise-Legacy-Systeme und gRPC für performante Microservice-Kommunikation — alle in n8n nutzbar.
Für Entwickler entscheidet die API-Flexibilität darüber, ob ein Automatisierungstool langfristig tragfähig ist. n8n erlaubt dir, auf Protokollebene einzugreifen, während Make die meisten API-Interaktionen hinter visuellen Modulen abstrahiert. Das ist bequem, kann aber bei spezifischen Anforderungen zum Engpass werden.
REST, SOAP, gRPC: Was n8n im Backend leistet
Die Wahl des API-Protokolls beeinflusst Performance und Kompatibilität deiner Workflows direkt. n8n unterstützt alle drei gängigen Standards und gibt dir die Freiheit, je nach Anwendungsfall das passende Protokoll zu wählen.
| Protokoll | Latenz | Typischer Einsatz | n8n-Unterstützung |
|---|---|---|---|
| REST | Mittel | Web-APIs, CRUD-Operationen | Nativ (HTTP Request Node) |
| SOAP | Höher | Enterprise-Systeme, Legacy | Über XML-Konfiguration |
| gRPC | Niedrig | Microservices, Echtzeit-Daten | Über Custom Nodes |
Laut dem Performance-Vergleich von Predic8 bietet gRPC deutliche Vorteile bei kleinen Payloads und hoher Frequenz. Für n8n-Workflows, die große Datenmengen zwischen Microservices bewegen, kann die Protokollwahl die Ausführungszeit messbar verkürzen.
REST bleibt der Standard für die meisten Integrationen. Doch wenn du skalierbare API-Architekturen aufbaust, lohnt sich ein Blick auf gRPC, besonders bei interner Kommunikation zwischen Services. Mehr zur Entwicklung skalierbarer API-Architekturen findest du in unserem Leistungsbereich.
HTTP-Methoden korrekt nutzen: PUT vs. PATCH in der Praxis
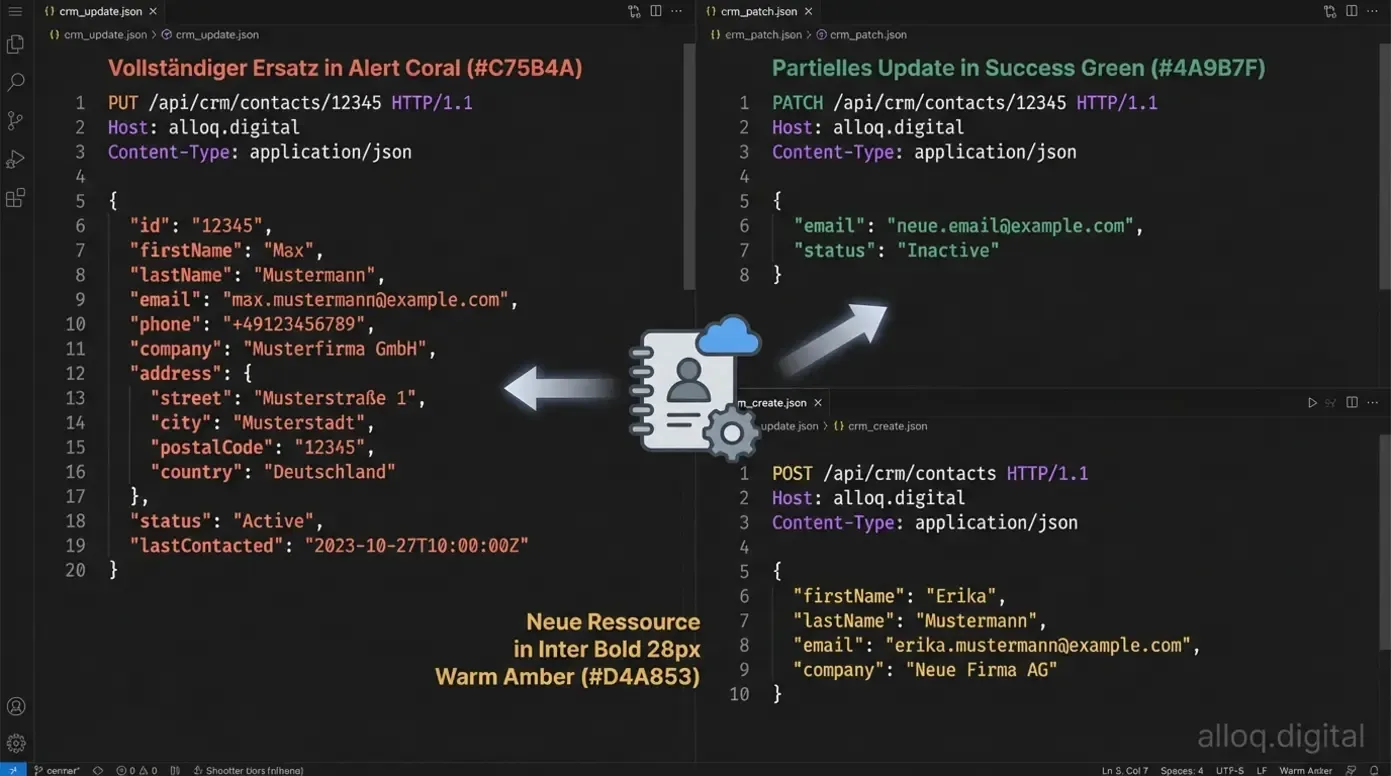 PUT sendet alle Felder und ersetzt komplett, PATCH aktualisiert nur geänderte Felder — bei Tausenden API-Calls täglich ein erheblicher Performance-Unterschied.
PUT sendet alle Felder und ersetzt komplett, PATCH aktualisiert nur geänderte Felder — bei Tausenden API-Calls täglich ein erheblicher Performance-Unterschied.
Ein häufiger Fehler in Automatisierungsworkflows ist die falsche Wahl der HTTP-Methode. Der Unterschied zwischen PUT und PATCH klingt subtil, hat aber konkrete Auswirkungen auf Effizienz und Datenintegrität.
PUT ersetzt eine Ressource vollständig. Wenn du ein Kundenprofil mit PUT aktualisierst, musst du alle Felder mitsenden, auch die unveränderten. PATCH ändert nur die angegebenen Felder. Laut der offiziellen SelfHTML Dokumentation ist PATCH die richtige Wahl für partielle Updates.
In n8n-Workflows bedeutet das: Nutze PATCH, wenn du einzelne Felder in einem CRM aktualisierst. Nutze PUT nur, wenn du sicherstellen willst, dass der gesamte Datensatz durch deine Version ersetzt wird. POST bleibt für das Erstellen neuer Ressourcen reserviert. Diese Unterscheidung kann bei Workflows mit Tausenden von API-Calls pro Tag die Payload-Größe und damit die Performance deutlich verbessern.
Apple Silicon Prozessor-Vergleich (Hardware für Self-Hosting)
 Hardware-Guide für lokales KI-Hosting: Der M2 mit 16 GB RAM bietet das beste Preis-Leistungs-Verhältnis für n8n + Ollama — der M3 mit 24 GB ist erst bei 30B+ Modellen nötig.
Hardware-Guide für lokales KI-Hosting: Der M2 mit 16 GB RAM bietet das beste Preis-Leistungs-Verhältnis für n8n + Ollama — der M3 mit 24 GB ist erst bei 30B+ Modellen nötig.
Wer n8n im Self-Hosting betreibt und lokale KI-Modelle über Ollama anspricht, braucht passende Hardware. Apple Silicon hat sich als pragmatische Lösung für datenschutzbewusste Entwickler etabliert, die keine teuren GPU-Server mieten möchten.
Self-Hosting Performance: M1 vs. M2 vs. M3 für lokale LLMs
Die Leistungsunterschiede zwischen den Apple-Silicon-Generationen sind für n8n-Workflows relevant, aber nicht immer entscheidend. Der M1-Chip reicht für einfache n8n-Instanzen mit moderatem Durchsatz. Für lokale LLMs über Ollama wird die Unified Memory Architecture zum Flaschenhals.
Der M1 mit 8 GB RAM kann kleine Modelle (7B Parameter) ausführen, stößt aber bei parallelen Anfragen an Grenzen. Der M2 verbessert die Memory-Bandbreite um etwa 50%, was sich bei gleichzeitigen Workflow-Executions und LLM-Inferenz bemerkbar macht. Der M3 bringt zusätzlich eine leistungsfähigere GPU-Architektur mit, die laut Head4Space (2024) das Zusammenspiel von n8n und Ollama auf Apple Silicon spürbar beschleunigt.
Für die meisten Self-Hosting-Szenarien mit n8n und einem lokalen 7B- oder 13B-Modell bietet der M2 mit 16 GB RAM ein gutes Verhältnis aus Leistung und Kosten. Wer regelmäßig größere Modelle (30B+) lokal nutzen will, sollte mindestens zum M3 mit 24 GB greifen.
Upgrade-Check: Lohnt sich M4/M5 für n8n-Server?
Die Frage, ob sich ein Upgrade auf die neueste Chip-Generation lohnt, hängt von deinem tatsächlichen Workload ab. Für typische n8n-Automatisierungen, also Datenabfragen, Transformationen und API-Calls, ist selbst ein M1 ausreichend. Die CPU-Last bleibt bei den meisten Workflows gering.
Der Mehrwert neuerer Generationen zeigt sich erst bei GPU-intensiven Aufgaben: lokale LLM-Inferenz, Bild-Generierung oder parallele Verarbeitung großer Datenmengen. Wenn du einen dedizierten n8n-Server mit Ollama betreibst und regelmäßig KI-Modelle lokal ansprichst, kann der Sprung auf M4 die Antwortzeiten verkürzen. Für reine Workflow-Automatisierung ohne lokale KI reicht ein M2 oder M3 auf absehbare Zeit.
Der pragmatische Ansatz: Starte mit der Hardware, die du hast. Messe die tatsächliche Auslastung. Investiere erst in ein Upgrade, wenn du konkrete Engpässe dokumentieren kannst.
Gartner (2025) prognostiziert, dass bis zu 30% aller KI-Projekte in Unternehmen scheitern werden. Die Hauptgründe sind nicht technologischer Natur, sondern liegen in mangelnder Strategie, unzureichender Datenqualität und fehlender Integration in bestehende Prozesse. Diese Erkenntnisse unterstreichen, warum die Wahl des richtigen Automatisierungstools eine strategische Entscheidung ist.
In unserer Agentur sehen wir oft, dass Teams mit dem falschen Tool starten und nach sechs Monaten migrieren müssen. Simon betont: „Der größte Kostenfaktor ist nicht das Tool selbst, sondern die verlorene Zeit bei einer späteren Migration. Wer die Architektur-Entscheidung am Anfang richtig trifft, spart langfristig.”
Dieses technische Verständnis von Fair-Code-Lizenzen, API-Standards und Hosting-Optionen hilft dir, eine Entscheidung zu treffen, die über die nächsten zwei bis drei Jahre Bestand hat. Die reine Tool-Bedienung lernst du in einer Woche. Die Architektur-Entscheidung wirkt jahrelang.
Risiken, Grenzen & Alternativen
 Ehrliche Risikoanalyse: Self-Hosting ohne DevOps-Know-how ist gefährlich, und Low-Code löst 80% der Aufgaben — für die restlichen 20% braucht man professionelle Unterstützung.
Ehrliche Risikoanalyse: Self-Hosting ohne DevOps-Know-how ist gefährlich, und Low-Code löst 80% der Aufgaben — für die restlichen 20% braucht man professionelle Unterstützung.
Automatisierung verspricht Effizienz, doch kein Tool löst alle Probleme. Wer die Grenzen kennt, trifft bessere Entscheidungen und vermeidet teure Fehleinschätzungen.
Wann Self-Hosting zum Sicherheitsrisiko wird
Self-Hosting gibt dir Kontrolle, überträgt dir aber auch die volle Verantwortung für Sicherheit. Das Bundesamt für Sicherheit in der Informationstechnik (BSI) weist darauf hin, dass beim Eigenbetrieb die Verantwortung für Sicherheitsupdates und Konfiguration vollständig beim Betreiber liegt. Vergessene Updates, offene Ports oder fehlerhafte SSL-Konfigurationen können deine n8n-Instanz angreifbar machen.
Wenn du kein DevOps-Know-how im Team hast, ist Self-Hosting riskanter als hilfreich. In diesem Fall ist die Cloud-Version von n8n oder Make die sicherere Wahl. Vorsicht auch vor dem „Zero-Maintenance”-Versprechen: Jede Automatisierung braucht regelmäßige Wartung, API-Endpunkte ändern sich, Authentifizierungen laufen ab, Datenformate werden aktualisiert.
Die Grenzen von Low-Code (Wann man einen Entwickler braucht)
Low-Code-Plattformen lösen 80% der typischen Automatisierungsaufgaben. Für die restlichen 20% brauchst du oft professionelle Unterstützung:
- Komplexe Datentransformationen: Wenn du Daten aus verschiedenen Quellen normalisieren und in Echtzeit validieren musst, stoßen visuelle Builder an Grenzen
- Custom API-Authentifizierung: OAuth2-Flows mit Token-Rotation oder proprietäre Auth-Methoden erfordern Code-Kenntnisse
- Performance-kritische Workflows: Bei Verarbeitung von Millionen Datensätzen kann ein dedizierter Microservice effizienter sein als ein Low-Code-Workflow
Für diese „Last-Mile”-Probleme lohnt sich die Zusammenarbeit mit einem Entwickler. Der pragmatische Weg: Baue den Prototyp in n8n oder Make, identifiziere die Engstellen und hole erst dann technische Hilfe.
Häufig gestellte Fragen (FAQ)
Was ist der Unterschied zwischen n8n und Make?
Der Hauptunterschied liegt im Hosting und Preismodell. Make ist eine Cloud-Lösung (SaaS), die pro Operation abrechnet und sehr einsteigerfreundlich ist. n8n ist eine Fair-Code-Plattform, die Self-Hosting ermöglicht und pro Workflow-Durchlauf (Execution) abrechnet, was sie bei hohen Volumina günstiger macht.
Sollte ich n8n oder Make nutzen?
Wähle Make, wenn du ohne Programmierkenntnisse schnelle Ergebnisse willst. Es ist ideal für Marketing- und Sales-Teams mit überschaubarem Volumen. Entscheide dich für n8n, wenn du technisches Verständnis hast, komplexe Datenmengen verarbeitest oder volle Kontrolle über deine Daten (DSGVO) benötigst.
Ist Make.com einfacher als n8n?
Ja, Make gilt allgemein als einsteigerfreundlicher. Die visuelle Oberfläche ist intuitiver und erfordert weniger technisches Vorwissen. n8n bietet mehr Flexibilität und Tiefe, hat aber eine steilere Lernkurve, besonders wenn man JavaScript-Funktionen oder Custom Nodes nutzen möchte.
Ist n8n für Anfänger geeignet?
n8n ist zugänglich, erfordert aber Einarbeitung. Dank Vorlagen und einer aktiven Community können auch Einsteiger Workflows bauen. Das volle Potenzial erschließt sich jedoch erst mit technischem Grundverständnis. Für absolute Neulinge ohne IT-Affinität ist der Einstieg oft herausfordernder als bei Make.
Welches Tool ist besser für KI-Workflows?
Für komplexe KI-Agenten ist n8n oft überlegen. Durch die native Integration von LangChain und Python-Support lassen sich fortsrittliche Logiken und Human-in-the-loop-Architekturen bauen. Make eignet sich für standardisierte KI-Aufgaben, stößt aber bei hochkomplexen Agenten-Architekturen eher an Grenzen.
Fazit
Die Entscheidung make vs n8n ist keine Frage von „besser oder schlechter”, sondern von strategischer Passung. Make ist die richtige Wahl für Teams, die schnell starten wollen, ohne sich um Infrastruktur zu kümmern. Die intuitive Oberfläche und das SaaS-Modell machen den Einstieg unkompliziert. n8n richtet sich an technisch versierte Nutzer, die Skalierbarkeit, Datenkontrolle und KI-Flexibilität priorisieren.
Der Kern dieses Vergleichs lässt sich auf zwei Prinzipien reduzieren. Erstens: Automatisierung muss sich rechnen. Die 30%-Regel zeigt, dass erst ab einem signifikanten Automatisierungsgrad der geschäftliche Effekt spürbar wird. Plane deine Kosten also nicht für heute, sondern für das Volumen in zwölf Monaten. Zweitens: Datenhoheit ist kein Nice-to-have. Für europäische Unternehmen kann Self-Hosting den entscheidenden Unterschied bei der DSGVO-Konformität machen.
Starte mit einem kleinen Projekt und messe die Ergebnisse. Wenn du merkst, dass dein Automatisierungsbedarf über einfache Workflows hinauswächst, hast du mit n8n eine Plattform, die mitwächst. Wenn Einfachheit und Geschwindigkeit Priorität haben, liefert Make zuverlässige Ergebnisse. In beiden Fällen gilt: Plane die Skalierung von Anfang an mit ein.